


Let’s explore some of the key features available in Azure Synapse Analytics Notebooks. In this blog post, you’ll learn how to start using Notebooks.
Table of Contents
Some of the key benefits of using Notebooks are:
- Performing advanced data analytics workloads, including streaming using Notebooks and Spark pools
- Timely actionable insights
- Analyzing unstructured data, including Parquet or Json files
- Combining code with explanations
The following languages are available in Notebooks:
- PySpark (Python)
- Spark (Scala)
- .NET Spark (C#)
- Spark SQL

Creating a Notebook
To start, you can create a new Notebook in the Manage Hub.

Or you can simply query some files from the Data Hub.

This second option is going to prepare some code for you to start consuming data.

Next, if your Spark pool isn’t running, the first time will take some time to start. Remember that you are only charged for the usage time of the Spark pool.

At the notebook level, you have the following options:

I’d like to highlight that the Export option will generate a .ipynb file that you can use across platforms if required.
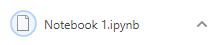
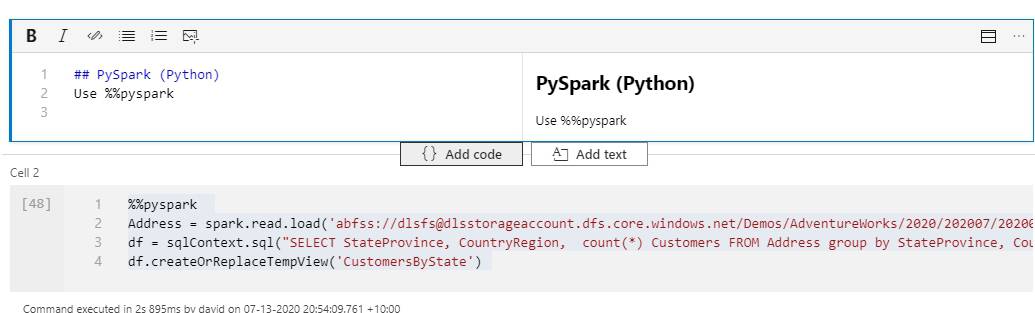
Additionally, you can also combine code with explanations.

Finally, to execute the Notebook, you must attach it to your Apache Spark Pool.

Cells
Within each cell, you have the following options:

Languages
You can combine the 4 languages using temporal tables. All of them will execute in the Spark context. Use the following magic commands to change languages.
- PySpark use %%pyspark
- Spark use %%spark
- .NET Spark use %%csharp
- Spark SQL use %%sql
Tutorial – Combine 4 Languages in One Notebook
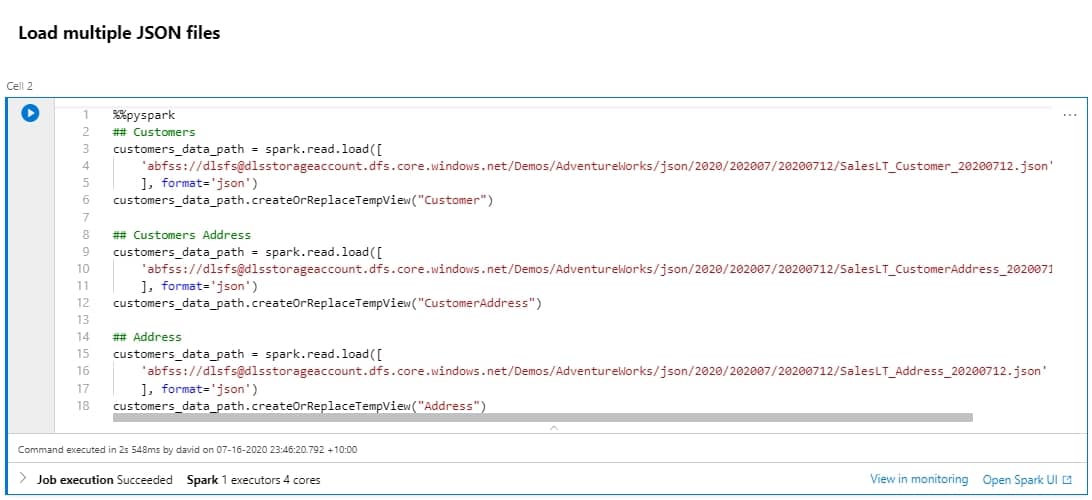
In the following tutorial, let’s use the “SalesLT_Address_20200709.parquet” file I created as part of the tutorial in my previous blog post.
Today’s tutorial will cover how you can combine the 4 languages in one Notebook.
You can also download the sample file and notebook file from here.
PySpark
%%pyspark
Address = spark.read.load('abfss://[email protected]/Demos/AdventureWorks/2020/202007/20200709/SalesLT_Address_20200709.parquet', format='parquet')
df = sqlContext.sql("SELECT StateProvince, CountryRegion, count(*) Customers FROM Address group by StateProvince, CountryRegion")
df.createOrReplaceTempView('CustomersByState') 
Spark SQL
%%sql:
CREATE TEMPORARY VIEW CustomersByCountry
AS (select CountryRegion as Country, sum(Customers) as Customers
from CustomersByState group by CountryRegion) 
%%sql:
select * from CustomersByCountry 
Spark Scala
%%spark
val ScalaTable = spark.sql("select Country from CustomersByCountry order by Customers asc limit 1")
ScalaTable.createOrReplaceTempView("CountryWithLessCustomers")
display(ScalaTable) 
.NET Spark (C#)
%%csharp
SparkSession spark = SparkSession
.Builder()
.AppName("SQL basic example using .NET for Apache Spark")
.GetOrCreate();
DataFrame sqlDf = spark.Sql("SELECT * FROM CountryWithLessCustomers");
sqlDf.Show(); 
Summary
To sum up, in today’s post we haven’t spent much time looking at all the benefits of using different languages, but you’ve seen how easy it is to get started in Azure Synapse Analytics Notebooks. It’s a very similar experience to using Azure Jupyter Notebooks or Azure Databricks.
Final Thoughts
All things considered, Notebooks have been around for a few years. Having them available in Azure Synapse Analytics will significantly increase their popularity among data scientists and data analysts.
What’s Next?
Looking forward, I’ll continue introducing new features that are already available in Azure Synapse Analytics Workspaces. Please leave me a comment if you have any questions!

1 Response
Lakshmi
23 . 06 . 2022Hi,
Can we run multiple cells in parallel in a synpase notebook