Searching for a way to create an Azure Data Factory but don’t know where to start? No worries! In this post, I’ll show you the ins and outs of creating an Azure Data Factory with ease.
Azure Data Factory is a cloud-based (PaaS) data integration service that allows businesses to create, manage, monitor, and secure data pipelines of any complexity. It’s one of the most powerful services within Azure, allowing you to move and transform data in near real-time—no matter the size or scope.
Whether you’re new to the Azure platform or a seasoned pro looking for tips on creating an efficient workflow, this article will give your pipeline creation process a jumpstart. You’ll take a look into the steps involved in creating an Azure Data Factory to help you better understand how it works.
Table of Contents
What Is Azure Data Factory?
Azure Data Factory (ADF) is a cloud-based data integration service that allows you to create data-driven workflows to orchestrate and automate data movement and transformation. In other words, it’s the perfect solution for anyone who needs to combine data from disparate sources, transform it into meaningful insights, and share it with others.
Using ADF is simple–you can create workflows simply by dragging and dropping components onto a canvas. The result? A robust solution that easily schedules graphical pipelines with numerous actions to process your data. Plus, you have the flexibility to execute your pipelines in either Azure or on-premises environments.
In short, ADF is an incredibly powerful and easy-to-use tool for creating intelligent solutions to process and analyze all sorts of data.
Create Azure Data Factory
As an Azure user, you can easily create your Azure Data Factory (ADF) and integrate it with other services. Creating an Azure Data Factory is the first step in creating and managing data-driven workflows in the cloud.
You can create an ADF using the Azure portal, Azure PowerShell, or the Azure CLI. Here’s how to get started:
Log into the Azure portal.
Select Create a resource, then select Data + Analytics, and then choose Data Factory.
Configure the essential information.

You can configure the connection with code version control as part of the creation, recommended for enterprise scenarios. You can also do it later (Enable Azure DevOps in Synapse or Data Factory).

It’s recommended to enable managed virtual networking for enterprise scenarios (pricing is different with managed virtual networks).

Enable encryption with customer-managed keys if required.

Add some tags to administer the service in Azure correctly.

Review and create your Azure Data Factory!

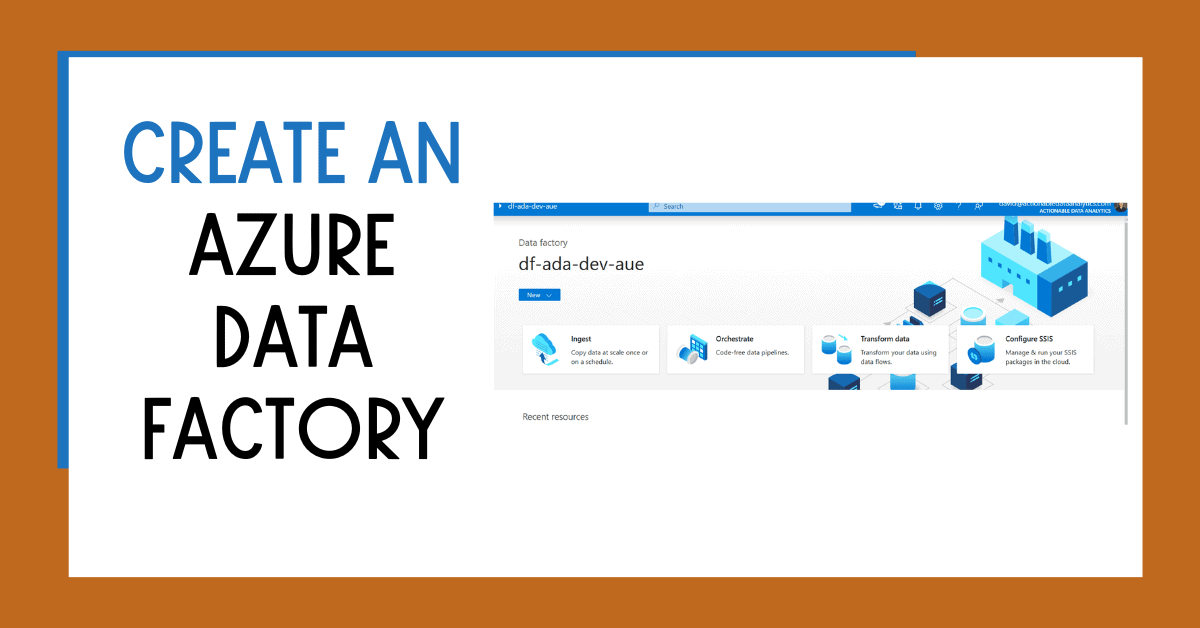
Once the provisioning is complete, you will see your new data factory instance in your resource group’s list. You can navigate to the studio from the service or the web URL https://adf.azure.com

You will end on the homepage.

Now that you’ve created your ADF instance, you are ready to begin configuring it by adding pipelines and datasets so you can build data-driven workflows using some of the tutorials in no time.
Benefits of Using Azure Data Factory
After using Azure Data Factory for more than five years, I can confidently say that there are many benefits of using Azure Data Factory. First, you can build complex data pipelines quickly and reliably and manage, monitor, and secure your data in the cloud without any headaches. Here are some of the other benefits of using Azure Data Factory:
Easy Data Integration: with Azure Data Factory, it’s easy to integrate data from various sources, such as on-premises data, cloud data, and hybrid data. This eliminates the need for complex coding or custom development.
Scalability: Azure Data Factory is a scalable solution that can process large volumes of data quickly and efficiently. This makes it suitable for large enterprises with big data requirements.
Flexible Data Orchestration: Azure Data Factory provides a flexible and customizable workflow orchestration framework that allows you to create, schedule, and monitor data pipelines.
Cloud-Based Service: Azure Data Factory is a cloud-based service, meaning investing in on-premises infrastructure or managing hardware is unnecessary.
Cost-Effective: Azure Data Factory is a cost-effective solution for data integration, allowing you to pay only for the resources you use.
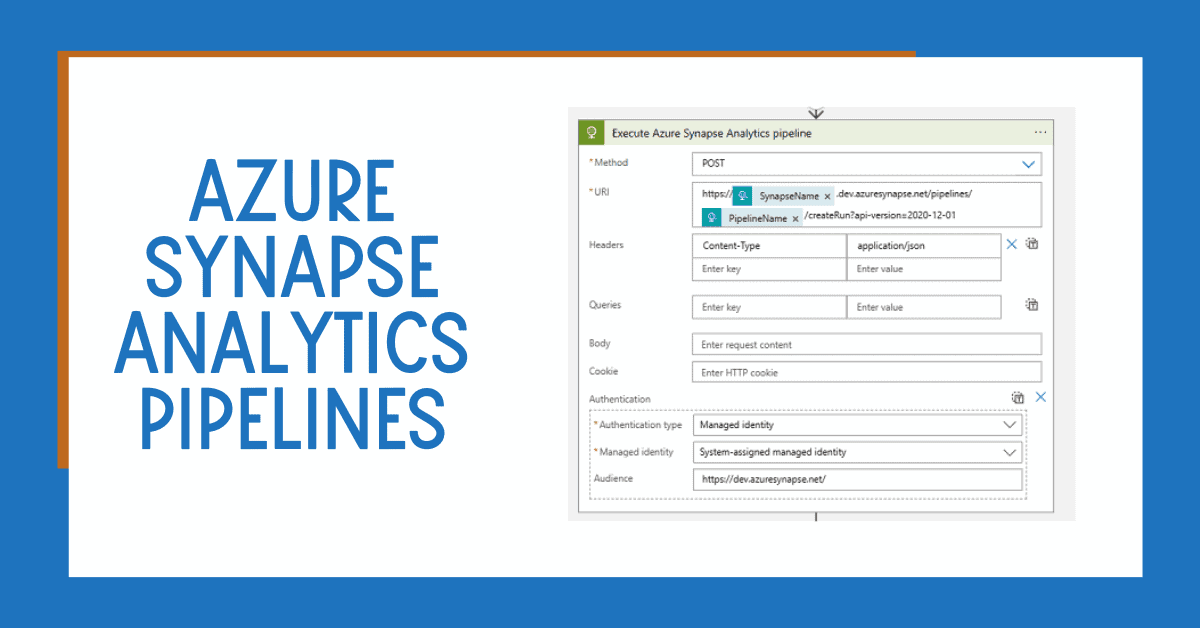
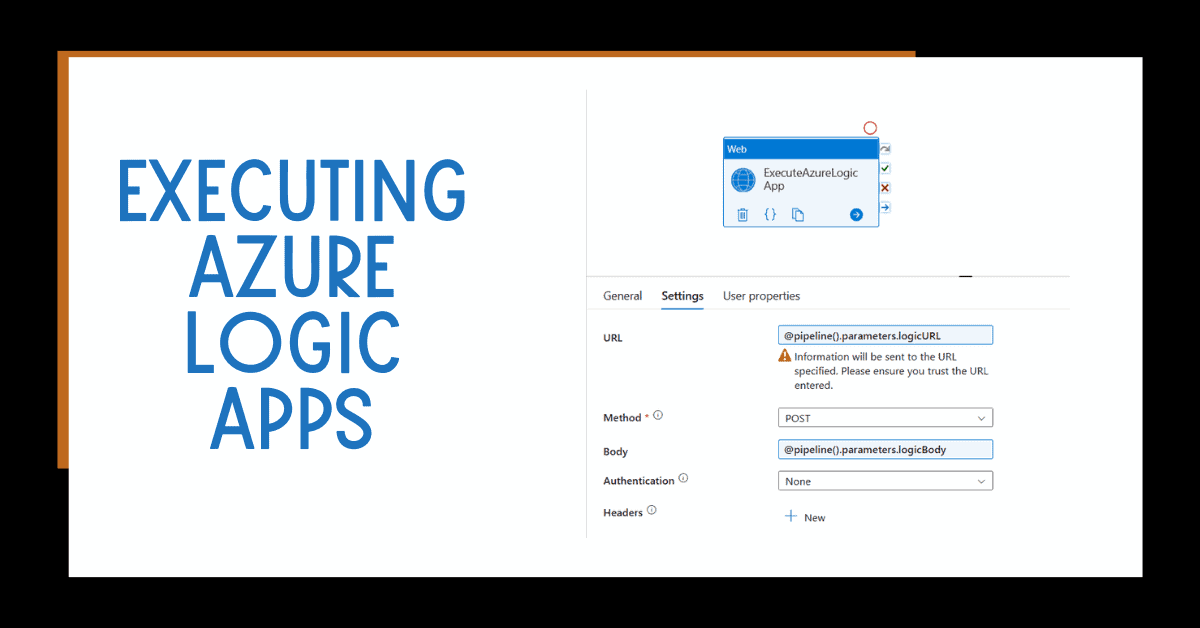
Integration with Azure Services: Azure Data Factory integrates seamlessly with other Azure services, such as Azure Synapse Analytics, Azure Databricks, and Azure HDInsight, allowing you to create end-to-end data processing solutions.
Security: Azure Data Factory provides robust security features, such as rest and transit encryption, to protect your data.
My intro blog post about using Azure Data Factory has more benefits.
Main Components Azure Data Factory
Azure Data Factory (ADF) is a robust cloud-based data integration service that helps you create data-driven workflows in the cloud. To get started with Azure Data Factory, you’ll need to be familiar with its two main components:
Linked Services
Linked services are the components in your Azure Data Factory that connect to other external systems—think of them as bridges between the source and destination systems. Linked services act like connectors, which you can use to read from and write data to a supported system.
Pipelines
Pipelines are the core components of ADF, as they define what needs to happen with our data as it flows from source to destination. Pipelines are made up of activities (more on this below), which are essential tasks you want your data factory to execute. You can then save these pipelines and use them whenever necessary!
You can build useful things using pipelines, like copying or transforming data from one location to another. Pipelines are the objecschedule periodic jobs or runsis.
Azure Data Factory Activities
Azure Data Factory (ADF) activities are the building blocks of data integration pipelines that perform data integration tasks such as data movement, data transformation, and data processing. In addition, there are several types of activities in Azure Data Factory that can be used to perform different tasks.
Data Integration Runtimes
Data Integration Runtimes are the compute resources that execute data integration pipelines. Azure Data Factory supports two types of runtimes: Azure Integration Runtime and Self-hosted Integration Runtime. Azure Integration Runtime is a fully managed runtime that runs in Azure. At the same time, a Self-hosted Integration Runtime is a runtime that runs on-premises or in a virtual private network (VPN).
Data Flows
Data Flows are a visual data transformation tool that allows you to create data transformation logic using a graphical interface. Data Flows provide a code-free and flexible way to develop data transformations.
Triggers
Triggers are the mechanism that initiates the execution of a pipeline. For example, you can create three types of triggers: schedule-based triggers, event-based triggers, and manual triggers.
The possibilities are endless!
Conclusion
In conclusion, creating an Azure Data Factory is relatively simple once you understand the basics. It requires a bit of preparation and the right tools, but it’s not overly complicated. Utilizing Azure Data Factory makes creating, managing, and monitoring data pipelines across various sources and databases more efficient and cost-effective. Take some time to learn the basics of Azure Data Factory, and you’ll be creating in no time.