


Are you looking at installing Self-Hosted Integration Runtime? Trying to import data from on-premises to Azure? Trying to publish data to on-premises systems using Azure Data Factory?
This tutorial will help you install Self-Hosted IR in Azure Synapse Analytics. It’s also valid for Azure Data Factory.
Self-Hosted Integration Runtime is designed so your on-premises systems are accessible to Azure services. This means they are accessible either when exporting data from on-premises systems to Azure or when exporting data from Azure to on-premises systems.
Table of Contents
Installing Azure Self-Hosted Integration Runtime
To start, there are 2 main steps to install IR. In addition, it’s possible to use PowerShell to do it.
- Creating Self-Hosted Integration Runtime in Azure
- Installing IR in an on-premises server / VM and syncing with your Azure Data Factory / Synapse Analytics
Creating Self-Hosted Integration Runtime in Azure
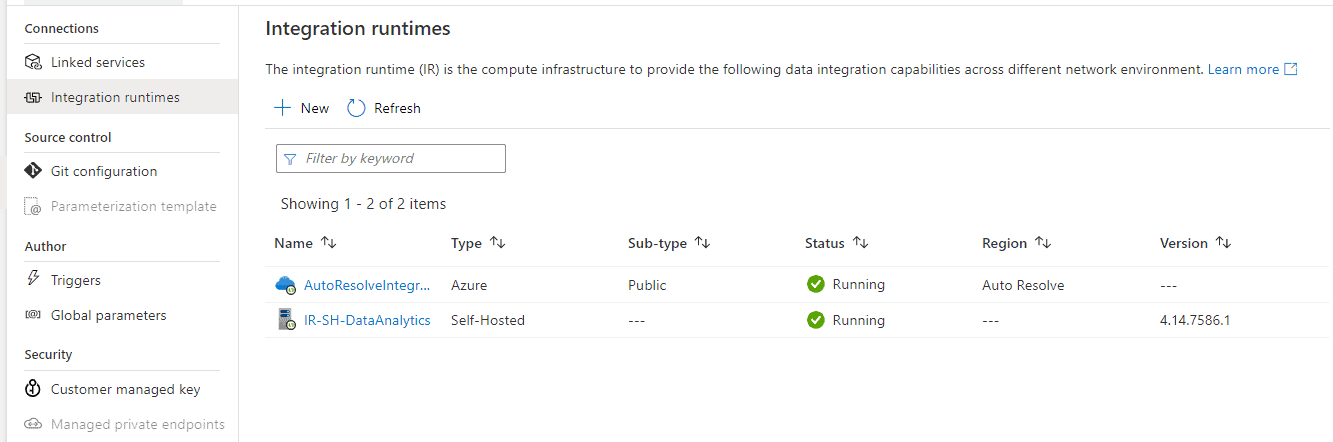
Next, in your Synapse Analytics, go to Manage-> Integration runtimes-> New

Then, select the Self-Hosted option and click “continue.”

After that, define a name and click and click “create.”

In the next screen, don’t forget to copy to the keys into your Key Vault. This allows you to re-install them in case of migration or problems.

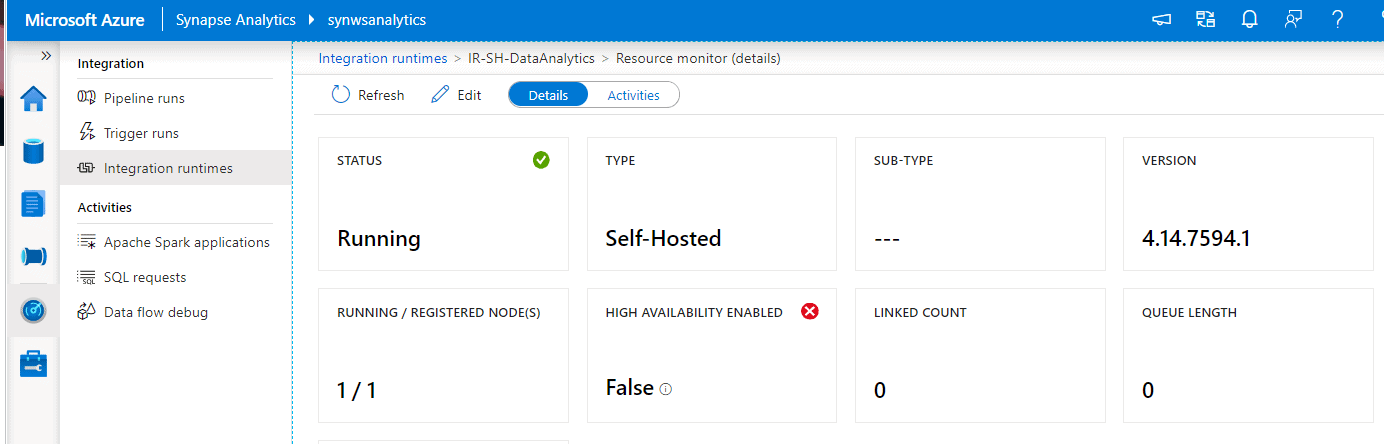
At this stage, you have already created a Self-Hosted Integration Runtime, but you need to finish the configuration by installing it in an on-premises server or virtual machine. Let’s go and finish the installation in the server.
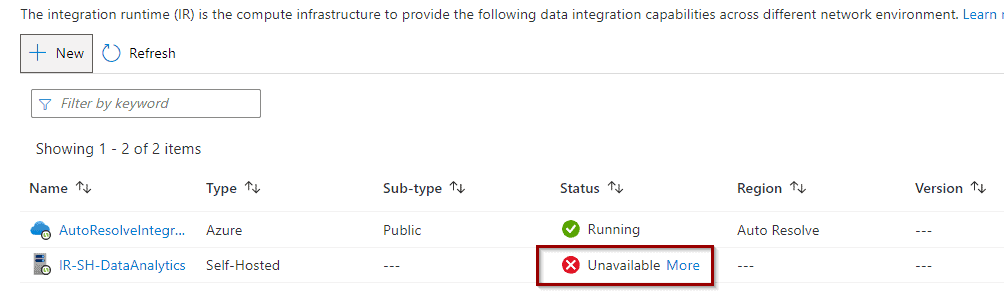
You can see that the IR is not available until we finish the next step.
Installing IR in an on-premises server / VM
This server/VM needs to be able to connect to access your source system so you can extract information from the on-premises systems.
You have 2 options:
- Express Setup – For this option, it downloads the installation file with the keys built into the file.
- Manual Setup – For this option, it downloads the installation file without the keys in the file. You need to follow a 2-step process:
- Install Service
- Include Keys to sync to Azure

Let’s follow the manual setup option.

Install Service
Next, once you download and open the file, you can install the service.



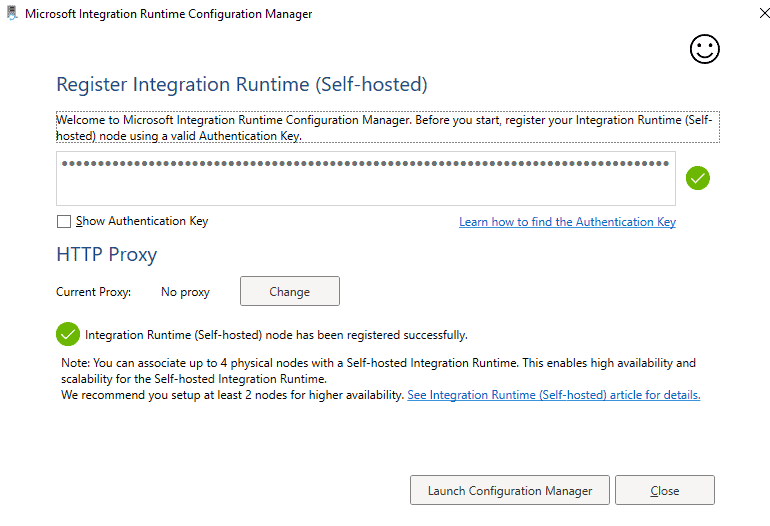
Include Keys to sync to Azure
Now, it’s time to sync with Azure by including keys.

Click “finish” and wait until it syncs with the Azure environment.

In the Azure portal, you can see the status as “available now.”

Configuring Azure Self-Hosted Integration Runtime
Within Azure Self-Hosted IR, you have some configuration options, for example:
- Enable clusters and define the maximum number of concurrent jobs
- Enable auto-update
- Monitor memory, version, and workloads
Enable clusters and define maximum number of concurrent jobs
First, you can enable a cluster. This is highly recommended for production workloads and increasing the limit of concurrent jobs.

Enable auto-update
Secondly, you can also enable auto-update of the Integration Runtime.

Monitor memory, version and workloads
Lastly, if you click the IR monitor icon or go to the Monitor Hub, you can see a summary of the status.

Summary
Today, you’ve installed and configured an Azure Data Factory Self-Hosted Integration Runtime. This enables workloads between on-premises systems and Azure without writing a single line of code.
What’s Next?
In upcoming blog posts, we’ll continue to explore Azure Data Factory Integration Runtimes and its features.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
Do you have any questions about Self-Hosted Integration Runtimes? Leave a comment below.

9 Responses
SIDNEY CIRQUEIRA
31 . 03 . 2021Hello David, how are you?
I’m trying to use shared self-hosted integration runtime on Azure Synapse Analytics. Do you know if is possible use it in any way?
David Alzamendi
06 . 04 . 2021Hi Sidney, it is not possible to share it with Azure Synapse Analytics at this stage. I am sure that we will see this feature in the upcoming releases.
Roxana O
04 . 05 . 2021Hello David,
I’m investigating how the repartition of concurrent jobs is done on multiple nodes of a self hosted integration runtime. Could you please help me with details on this matter?
Thank you!
David Alzamendi
04 . 05 . 2021Hi Roxana,
When you define multiple nodes for your Self-Hosted IR, you cannot select the node that you want to use for each workload, that’s manage by the service.
Example with 2 nodes (Node A and Node B):
If there is memory and CPU pressure in Node A, the execution of new pipelines will be re-direct to Node B.
If you reach the maximum number of concurent jobs in Node A, it will use Node B for new pipeline executions.
Let me know if I can expand the information further.
Regards,
David
Paul Sheldon
31 . 05 . 2021Hi David
I’ve successfully set up two VMs running the self-hosted IR. Everything looks good, green across the board, High Availability is enabled, both VMs appear in the SharedIntegrationRuntime tab in a running status. However while monitoring each node I’m seeing lots of activity on the Dispatcher/worker node, but nothing happening on the Worker node, the running jobs never goes above 1 and network traffic is virtually non-existent, whereas the Dispatcher/worker node is consistently hitting it’s max concurrent jobs. Any ideas what might cause this?
Regards
Paul
David Alzamendi
27 . 06 . 2021Hi Paul,
I haven’t seen this scenario before, but I will be setting up a HA Self-Hosted IR this week. I will keep you updated.
Regards,
David
Annu Kumari
03 . 10 . 2021Hi Paul,
I had this issue in my project . This happens when the first 15 characters of your nodes are same. The dispatcher will look for the node name upto first 15 characters to distribute the load. If possible can you give details about the node names you are using. It should be within 15 characters
Srini
09 . 09 . 2021I have a scenario where I need to load data from SQL Server hosted in Azure VM to ADLS GEN2 and vice versa.
Could you suggest which IR to be used and how to decide on multiple nodes?
jk
25 . 10 . 2021> First, you can enable a cluster. This is highly recommended for production workloads and increasing the limit of concurrent jobs.
So how do you actually enable clustering?