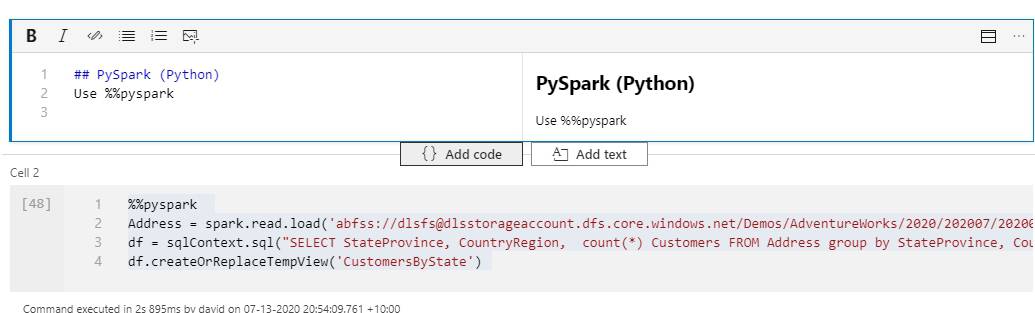
In this blog post, I’ll show you how to easily query JSON files with Notebooks by converting them to temporal tables in Apache Spark and using Spark SQL.
With the appearance of Data Lakes and other file formats in the data analytics space, people are curious about how to consume these new dataset formats. While a highly skilled technical resource can do it, you can also use Azure Synapse Analytics to get insights with a no-code experience or by writing only a few lines of code.
Table of Contents
Querying JSON Files Tutorial
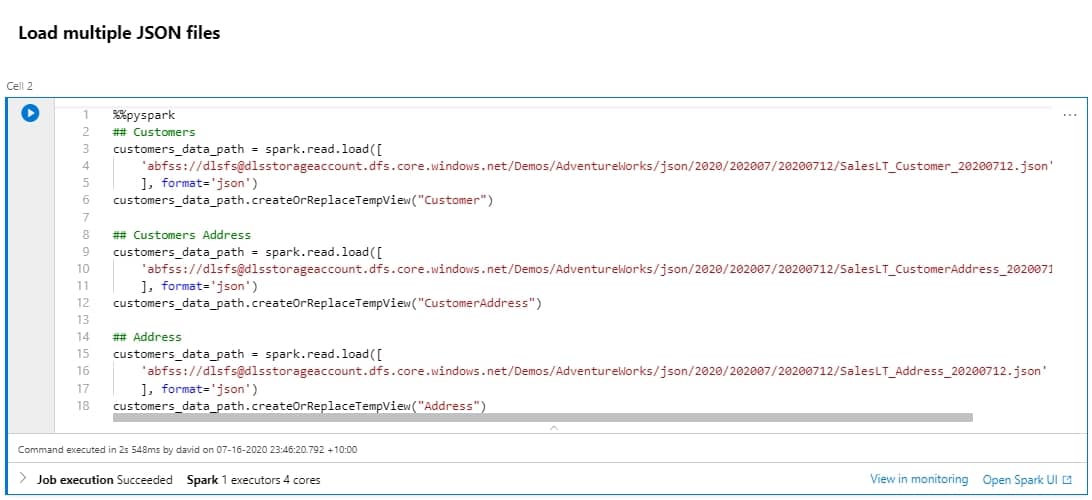
In this tutorial, we are going to be querying some files from the Adventure Works LT database. You can download the files and get a copy of the notebook.
%%pyspark
## Customers
customers_data_path = spark.read.load([
'abfss://[email protected]/Demos/AdventureWorks/json/2020/202007/20200712/SalesLT_Customer_20200712.json'
], format='json')
customers_data_path.createOrReplaceTempView("Customer")
## Customers Address
customers_data_path = spark.read.load([
'abfss://[email protected]/Demos/AdventureWorks/json/2020/202007/20200712/SalesLT_CustomerAddress_20200712.json'
], format='json')
customers_data_path.createOrReplaceTempView("CustomerAddress")
## Address
customers_data_path = spark.read.load([
'abfss://[email protected]/Demos/AdventureWorks/json/2020/202007/20200712/SalesLT_Address_20200712.json'
], format='json')
customers_data_path.createOrReplaceTempView("Address")

Next, after loading the files into temporal views, query them using Spark SQL.
%%sql
select CountryRegion, count(*) as NumberOfCustomers
from Customer CUS
join CustomerAddress CAD
on CUS.CustomerID = CAD.CustomerID
join Address ADR
on ADR.AddressID = CAD.AddressID
group by CountryRegion
order by count(*) desc

Is that it? Yes, that’s all! Now you are ready to start consuming your JSON files.
What if you have multiple files?
Query multiple files at the same time by using the wildcard such as *. For example:

Summary
To sum up, querying JSON files is not a challenging on this platform thanks to Notebooks. This enables data engineers, data scientists and data analysts to easily consume information using different file formats. In my opinion, it’s certainly one of the best features of Azure Synapse Analytics.
What’s next?
Looking forward, I’ll continue introducing new features that are already available in Azure Synapse Analytics Workspaces. Please leave me a comment if you have any questions.
My previous post: Azure Synapse Analytics Notebooks.
Another post on Azure Synapse Analytics: Create Parquet Files