



In this blog post, we will create Parquet files out of the Adventure Works LT database with Azure Synapse Analytics Workspaces using Azure Data Factory.
As part of this tutorial, you will create a data movement to export information in a table from a database to a Data Lake, and it will override the file if it exists. In upcoming blog posts, we will extend the functionality to do the same to multiple tables.
If you want to download the Adventure Works LT database, click here.
Table of Contents
The sections of this blog post:
- Why use Parquet files?
- Parquet files are open source file formats, stored in a flat column format released around 2013.
- Create linked services
- Linked services are the connectors/drivers that you’ll need to use to connect to systems. Azure Data Factory offers more than 85 connectors.
- Create datasets
- Datasets are the data asset that you are going to be working with like a table, file, or API URL.
- Create pipelines
- Pipelines are the activities that execute data movement.
- Test pipeline and consume data
- We will execute a pipeline and explore data with SQL scripts and notebooks.
Why use Parquet files?
Parquet files are open source file formats, stored in a flat column format (similar to column stored indexes in SQL Server or Synapse Analytics). The top 3 reasons why I believe you want to use Parquet files instead of other file types are:
- Querying and loading parquet files is faster than using common flat files
- Files are highly compressed
- Using the recommended file types prepares your platform for the future. Most big data analytics tools allow you to consume Parquet files
As you can see, the three reasons also help to decrease the on-going cost of your data platform.
Created Linked Services
I recommend using Managed Identity as the authentication type.
First, give Azure Synapse Analytics access to your database. In this case, you are only going to read information, so the db_datareader role is enough.
Execute this code (replace service name with the name of your Azure Synapse Analytics Workspaces):
create user [service name] from external provider exec sp_addrolemember 'db_datareader','service name' 
Give Azure Synapse Analytics access to your Data Lake.

Next, you are ready to create linked services. From your Manage Hub, click on the linked services to create them.

Then, create the first linked service for your source database.

Configure and test the connection for your database.

After that, create one linked service for your destination Data Lake.

Finally, configure and test the connection.

Create Datasets
You need to create a dataset for your source Azure SQL Database dataset and your destination Azure Data Lake parquet dataset.

Source dataset

Select your linked services but don’t choose any tables for now.

Destination parquet dataset

Select dataset format

Select your Data Lake linked service. You’ll see that you can only open the properties of the dataset. If necessary, add a parameter, change the compression type, or modify the schema.

Compression types for parquet files

Create a Pipeline
The last step of this tutorial is to create a pipeline to move information between your database and your Data Lake.

First, add a copy activity and finalize the configuration.

Then, configure your source by selecting the table or using the query. By not selecting the table in the dataset, you will have more flexibility to re-use the same dataset across different tables without creating 1 dataset per table.

Next, you need to define the dataset for your Data Lake that you have previously created.

You don’t need to modify mapping, settings and user properties for this tutorial.
Finally, publish the objects and trigger your pipeline.



Test pipeline and consume data
You are ready to trigger your pipeline. In the following scenario, you manually trigger the execution of the activity, but you can also define a schedule that executes the activity automatically.

From the Monitor Hub, you can see all the information about the execution.

Define a schedule if you’d like to execute the activity on a schedule basis.

The file will be available in your Data Lake.

Query with Serverless Azure Synapse Analytics.

Query the file.

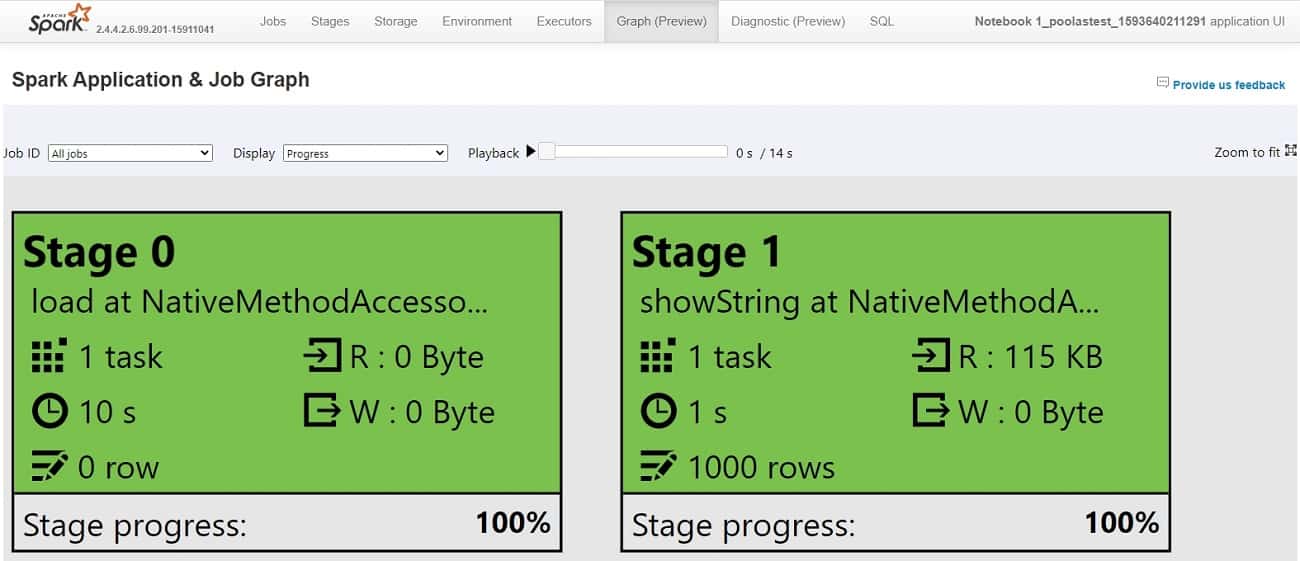
You can also query the information using notebooks.

Execute the notebook in your Apache Spark cluster.

Summary
Generating Parquet files with Azure Data Factory is easy and the capabilities are already built in, even offering different compression types. It’s not necessary to write a single line of code to start generating parquet files.
Final Thoughts
I think that parquet files are the format that we need to use going forward on our data platforms. This does not mean that they won’t change in a few years, but we need to adapt and use the best up-to-date technology.
What’s next?
If you want to see how to extend the functionality of this demo to export multiple tables to parquet files click here.

1 Response
Gilbert Quevauvilliers
15 . 07 . 2020Hi David, this is a great blog post but I am getting stuck when creating the user ‘synwsanalytics’
If you could let me know where I would go to create this user before I can add it into my SQL Server database?