



In this post, you’ll learn how to easily perform object replication between storage accounts in the same or different regions. This decreases the read latency from applications, users or any workload that requires reading files from a different region. It also helps you import files from different storage accounts into a central repository.
This is a great feature available for blob storage accounts. However, it isn’t available yet in Data Lake accounts (hierarchical namespaces).
Azure Storage Object Replication allows you to copy files asynchronously and can be managed by PowerShell and Azure CLI.
Look at the following image provided in Microsoft documentation:

Table of Contents
Enabling Object Replication
To begin, you can find “Object Replication” as an option within your storage account.

Once you open the object replication option, you’ll see a summary for the current replication configurations.

Setting up object replication rules
Next, let’s add a replication rule.

In this case, I will replicate information from a storage account in Australia East region to West US region. When you create a replication rule, change feed and versioning for the blogs are enabled automatically.

Select specific containers to replicate. You can configure the following options:
- Add filters based on a prefix rule. Wildcards are not supported.
- Select if you want to copy only new objects or existing objects as well
Add filters
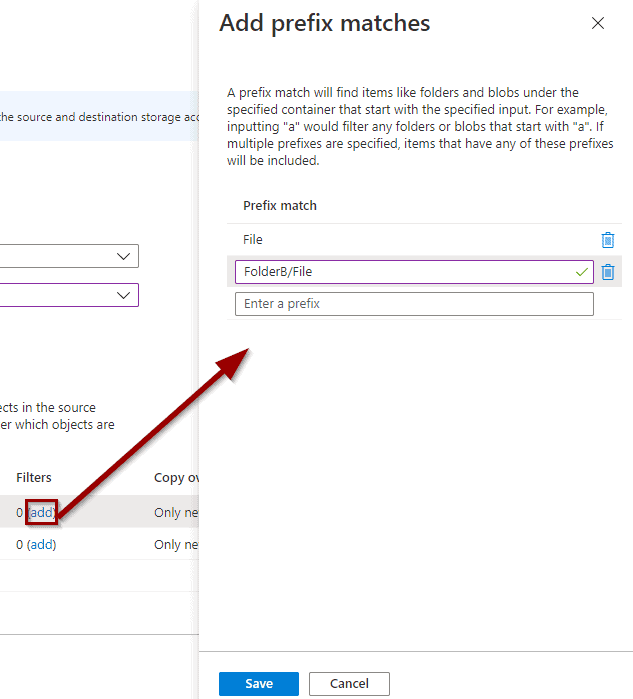
Define if you’d like to copy existing files, new files, or apply a custom rule.
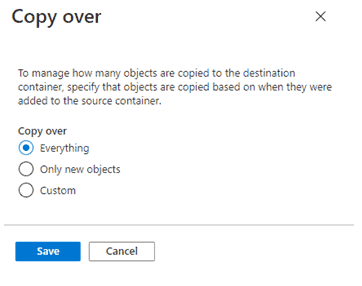
Now, you can save the rule.

You can see the replication rule that you’ve created.

Testing replication rules
To test a replication rule, I copied some empty files within one of the source containers. As you can see, FolderA will not meet the previously defined filter rules.

I also included some files that don’t meet the file name rules.

Now, let’s have a look at the destination storage account. Only the folder that meets the filter rules has been copied.

Once we open the folder, only the correct files have been copied. It took only 1 minute to kick-off the replication. The time depends on how busy the infrastructure is and how big the files are.

Enabling change feed and versioning manually
Finally, if you prefer to manually enable change feed and versioning, do it before or during account creation in the Data Protection section.

Summary
To sum up, today you learned how to replicate objects across different storage accounts by defining different rules using the Azure portal. You saw how it’s possible to do this without writing a single line of code!
Final Thoughts
This feature hasn’t been around for long, and it is definitely a great asset for some use cases. I expect to see wildcards enabled for the replication filter rules in the future, as well as support for Data Lakes.
What’s Next?
During the next few weeks, we will explore more features and services within the Azure offering.
Please follow me on Twitter at TechTalkCorner for more articles, insights, and tech talk!

2 Responses
Mircea
13 . 01 . 2021I tried finding some documentation related to how the failover to the secondary storage is handled in case of object replication. Does the client needs to design the application so that in case the primary is down the request is redirected to the secondary read-only storage or does the Azure handles that automatically? If latter, does this mean for each request the application must go initially to the primary storage in order to be redirected to the secondary storage?
Sorry if this is not the right place for these questions but I didn’t find any docs on Azure regarding this.
David Alzamendi
14 . 01 . 2021Hi Mircea,
Thank you for reading the article!
Good question, I am not sure if I understood the question, but I will try to answer it.
Without taking into account this feature:
When you create the storage account and at the storage account level, you defined the redundancy of the data, for example:
Locally redundant storage (LRS)
Zone-redundant storage (ZRS)
Geo-redundant storage (GRS)
Geo-zone-redundant storage (GZRS)
Objects are already being replicated at bear minimum 3 times within the same data centre (LRS), the redundancy can be increased by going to other options like ZRS, GRZ. Failovers and outages are managed by Microsoft. Also, Microsoft replicates the objects automatically.
Taking into account this feature:
With Azure Storage Replication, you get some control on which objects you replicate between different storage accounts. Now, each storage account could have different redundancy options, you could be replicating an object from a “storage account A” that uses LRS to another “storage account B” that uses ZRS. This will mean as well, that you will need to build logic in the application to try to read files from “storage account A” if “storage account B” is not available (maybe overkill if both storage accounts are using ZRS or GRS).
Recommended msdn documentation: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy
Happy to provide more information.