Automatically scaling Azure Synapse Analytics is a must for your data movement solutions. While we wait for this capability to be completely available and built into the service, I’ll show you how to easily implement this functionality using Azure Data Factory pipelines.
Table of Contents
Download solution to Scale Azure Synapse Analytics SQL Pool with Azure Data Factory
You can find 2 different solutions in this blog post:
- Solution for scaling Azure Synapse SQL Pool in Synapse Studio. Download JSON Definition here.
- Solution for scaling Azure Synapse Analytics SQL Pool as a standalone service (formerly known as Azure SQL Data Warehouse). Download JSON Definition here.
The reason for doing this is that the APIs are different.
The most amazing fact about this solution is that it’s synchronous. It won’t finalize until new resources have been allocated or deallocated. Check the definition of synchronous and asynchronous here.
Example data movement process:
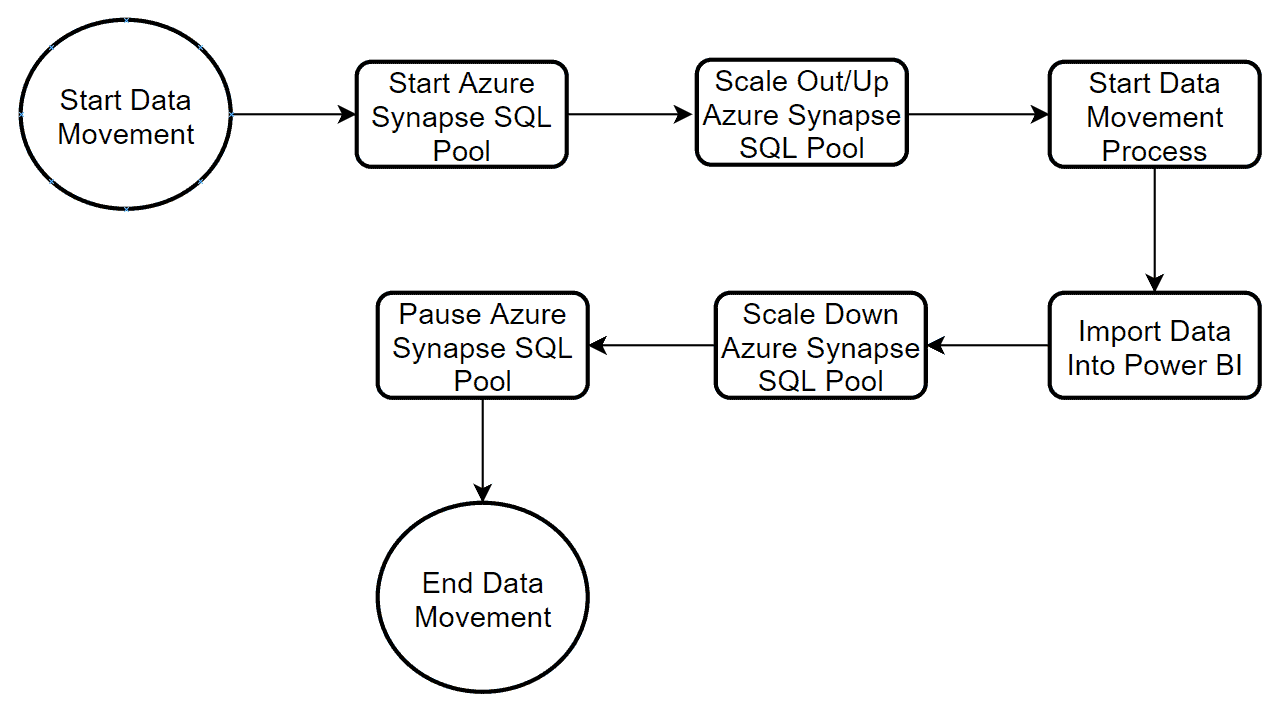
You can download the script to Pause and Resume Azure Synapse Analytics SQL Pool here.
Creating a reusable pipeline to scale Data Warehouse Units (DWUs)
To begin, Azure Data Factory can scale out resources for you by using an Azure Data Factory pipeline and Web Activity capabilities.
First, you need to create a new pipeline.

To make it reusable across different SQL Pools, create the following parameters. You can add a default value as well.

ServerName is the Azure Synapse Analytics workspace name when using a workspace SQL Pools solution.
Drag and drop Web activity into the pipeline. We will use Azure Synapse Analytics Workspace APIs and Azure Synapse Analytics (formerly known as Azure SQL Data Warehouse)APIs.

Now, let’s configure the Web Activity as follow.
Scale Azure Synapse Analytics SQL Pool in Synapse Studio
Next, in Azure Synapse Studio, configure the web activity using the following configuration. This solution is for SQL Pools created within Azure Synapse Analytics Workspaces.

1. REST API endpoint
@concat('https://management.azure.com/subscriptions/',pipeline().parameters.SubscriptionId,'/resourceGroups/',pipeline().parameters.ResourceGroupName,'/providers/Microsoft.Synapse/workspaces/',pipeline().parameters.ServerName,'/sqlPools/',pipeline().parameters.DatabaseName,'?api-version=2019-06-01-preview') 2. The method for this API endpoint needs to be PATCH.
3. HTTP Body
@concat(
'{
"sku": {
"name": ''',pipeline().parameters.DWU,'''
}
}'
) 4. Use MSI Authentification, if you want to know more about managed identities (check this blog post).
5. Resources to manage.
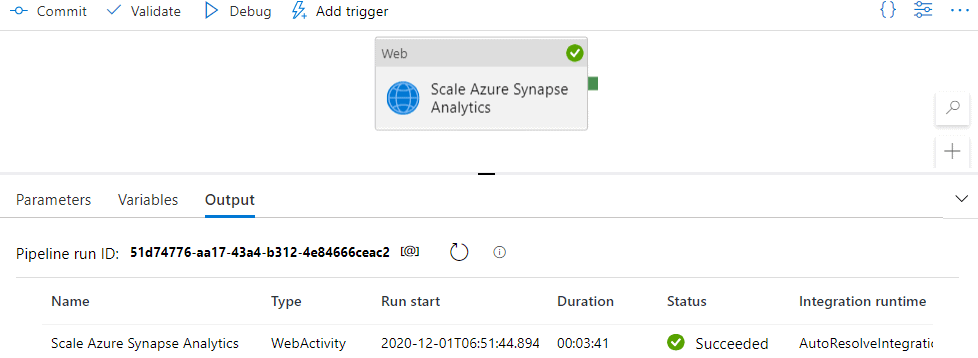
https://management.azure.com/ The pipeline is ready for testing! Click debug.
Scale Azure Synapse Analytics SQL Pool as a standalone service (formerly known as Azure SQL Data Warehouse)
If you are using Azure Synapse Analytics SQL Pools, you need to give Azure Data Factory or Synapse Analytics access to manage your SQL Pool using Azure role-based access control (RBAC).

Now, configure the Web activity using the following configuration.

1. REST API endpoint
@concat('https://management.azure.com/subscriptions/',pipeline().parameters.SubscriptionId,'/resourceGroups/',pipeline().parameters.ResourceGroupName,'/providers/Microsoft.Sql/servers/',pipeline().parameters.ServerName,'/databases/',pipeline().parameters.DatabaseName,'?api-version=2014-04-01-preview') 2. The method for this API endpoint needs to be PATCH.
3. HTTP Body
@concat(
'{
"properties": {
"requestedServiceObjectiveName": ''',pipeline().parameters.DWU,'''
}
}'
) 4. Use MSI Authentification, if you want to know more about managed identities (check this blog post).
5. Resources to manage.
https://management.azure.com/ The pipeline is ready for testing! Click debug.
Testing the pipeline
Finally, when testing the pipeline, it should work. You’ll see that it takes some time to perform the operation.

In the activity logs, you can also see the operation.
Summary
In summary, today you’ve created a reusable Azure Data Factory pipeline for scaling resources in your Azure Synapse Analytics SQL Pools. You can re-use it across any other existing workloads that you already have.
What’s Next?
In upcoming blog posts, we’ll continue to explore Azure Data Services features.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!