Azure Data Factory datasets allow you to define the schema and/or characteristics of the data assets that you are working with. Datasets can be static or dynamic. In this blog post, we’ll take a look at the main concepts and characteristics of using datasets.
Previously, I showed you different development methods using pipelines. When starting with Azure Data Factory, you need to have a good understanding of datasets.
Table of Contents
Creating Azure Data Factory Datasets
To start, in Azure Synapse Analytics Workspaces you can find datasets under the Data Hub.

To create one, click “new integration dataset.”

In Azure Data Factory, as a standalone service, you can find them under the Author option.

Then, create one by selecting the following option.

Then, select the type of dataset.

Next, define a name. Be careful! Once you publish it, you won’t be able to change it! Also, define a linked service and if you want to import the schema. Initially, I always recommend leaving it quite basic.

Main characteristics of a dataset:
- Connection properties
- Schema of the datasets
- Parameters
- General section for defining the name (Remember you cannot change this after publishing)
- Related objects to this dataset (Project Babylon!)
- Annotations to help you monitor any activities related to this dataset
- The definition of the dataset in JSON format
Types of Azure Data Factory Datasets when developing solutions
Secondly, let’s define 2 main dataset development types that help you understand different types of datasets.
It is important to understand that if you are working with 200 data assets from the same system, you want to avoid creating one dataset per data asset. Be more efficient and start working with parameters and dynamic content (dynamic datasets).
- Static dataset: a dataset for which the linked service and name have been defined and the schema has been imported.
- Dynamic dataset: a dataset for which the linked service has been defined, but the name and/or schema are dynamic.
Static Dataset
The schema name has been defined.

The schema (columns and data types) has been imported.

And there are not any parameters.

Dynamic Datasets
When developing most solutions, something needs to be dynamic within your datasets. It could be that you have parameters or you assign a query and/or schema in pipeline activities.
Let’s start with parameters first.
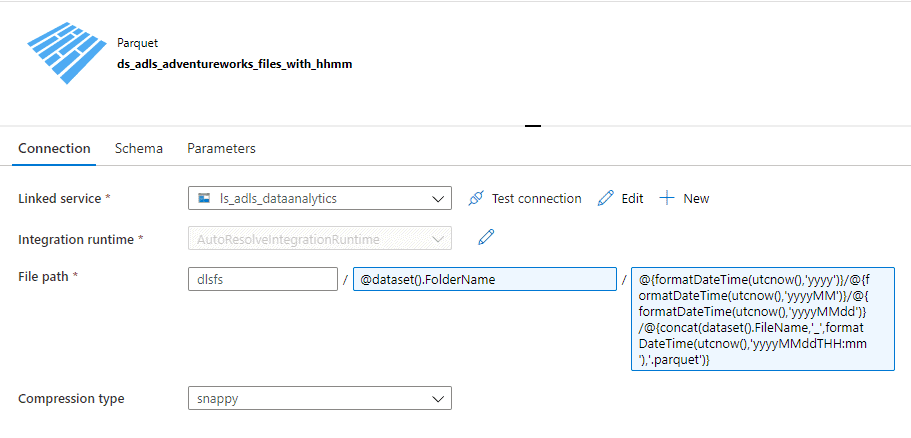
Define parameters to dynamically change the name of your data asset. You can create any parameters with any name that fits your needs.
Dataset folder with mapped parameters.

Do you need to have parameters to create a dynamic dataset?
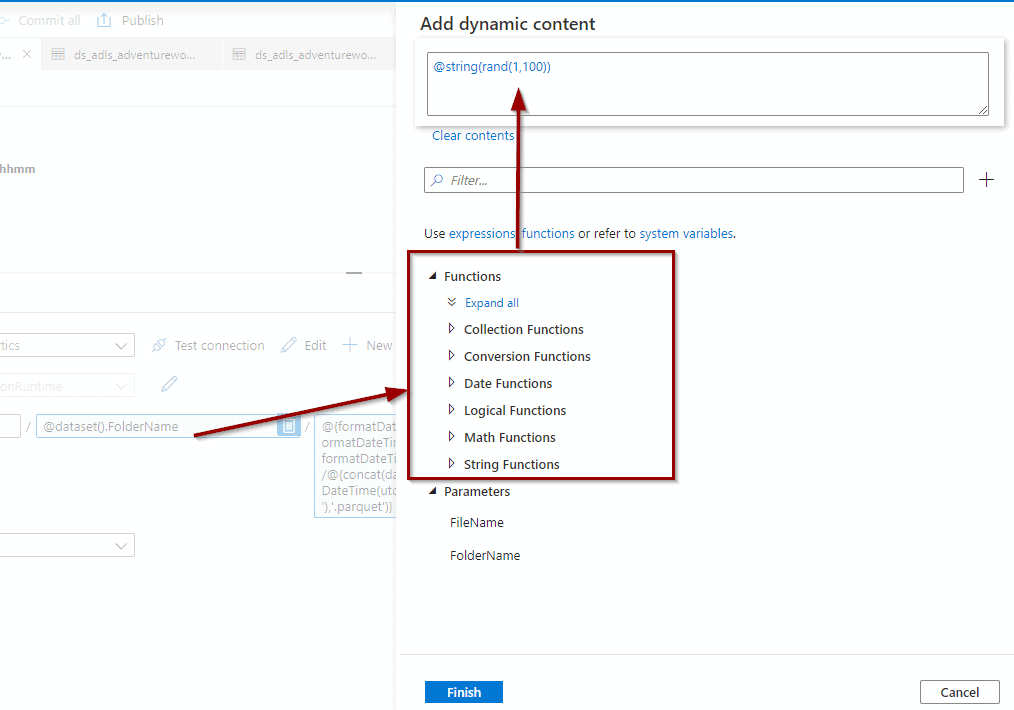
No, you can define a naming convention that generates a name using any of the functions available in the dynamic content. You can also define the dataset name in the pipeline activities.
Example of defining a dynamic name:
Example of defining the query in a copy activity:
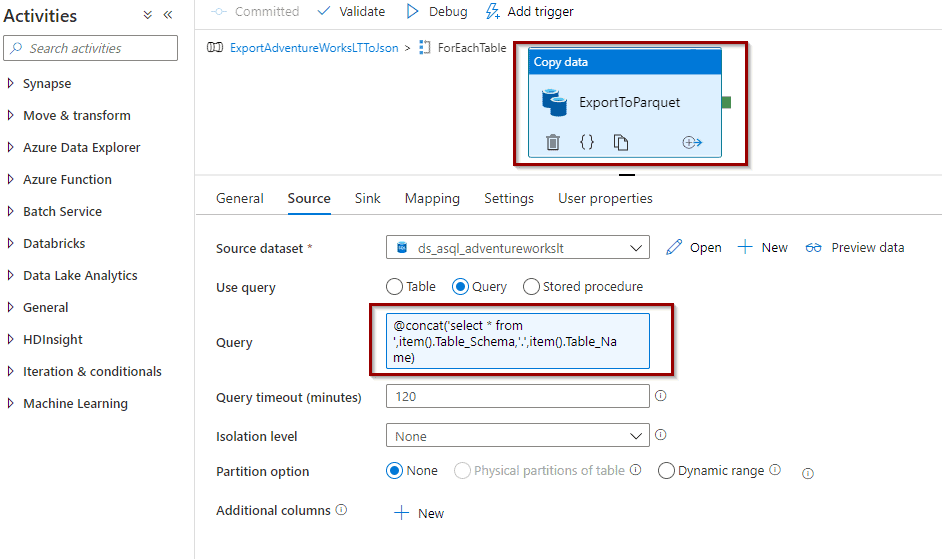
If the schema is not defined, this allows you to map columns/attributes between the source system and destination system automatically (the names must be the same) or assign it to an activity.
Scenario: running a copy activity without importing the columns schema. If you add one more column in the source system, it will be included in your data movement activities. Make sure the column is available in the destination system if you are working with tables or using a mechanism to identify schema drift.

Summary
Today, you’ve taken a look at Azure Data Factory datasets and the different types available for your solutions.
What’s Next?
In upcoming blog posts, we’ll continue to explore Azure Data Services features.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
If you have any questions, please leave a comment below!