


Are you starting with Azure Data Factory? Do you want to know more about Azure Data Factory pipelines, data flows and SSIS Integration Runtime? This guide covers the key differences between these and when you should choose each option.
Firstly, I recommend reading my blog post on ETL vs ELT before beginning with this blog post.
Table of Contents
Comparison
To begin, the following table compares pipelines vs data flows vs SSIS IR.
| Characteristics | Pipeline with Copy Activity | Data Flows | SSIS IR |
| Key Characteristics | Take advantage of the ELT approach and build large solutions using metadata-driven solutions. | Perform enterprise data transformations, aggregations, data cleansing without writing code (codeless) using a great web interface. | Great if you are looking at shifting your existing SQL Server Integration Services investment to a managed environment. |
| When to use? (Based on my experience) | Large environments along with existing SQL skills. | A codeless data movement solution or you aren’t worried about the cost. | An existing SSIS Investment. |
| Disadvantages | If you don’t have previous coding experience (SQL for example), it’s difficult to develop the transformations. | Not recommended if you aren’t performing transformations (just use copy activity) or if you are not working with medium to large volumes of data. | You can run into limitations with big volumes of data or if you want to load the data faster. |
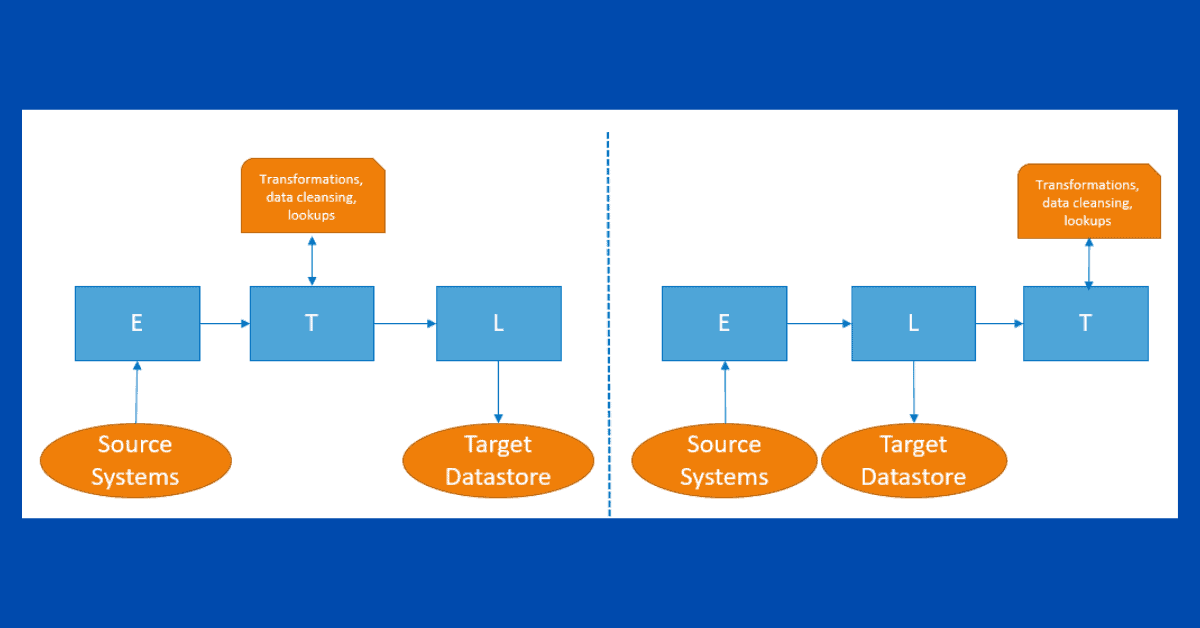
| Design pattern | ELT (Extract-Load-Transform) | ETL (Extract-Transform-Load) | ETL (Extract-Transform-Load) |
| Cost | Most cost-effective | Less cost-effective | Less cost-effective |
| Pay-per-use model | Yes | Yes | Yes |
| Large Volumes of Data | Yes | Yes | No |
| Engine | It relies on compute power in your source and target data stores, as well as Data Integration Units (DIUs) when using the Copy Activity | Apache Spark | SQL Server Integration Service |
| Codeless | Transformations require coding experience. | Yes | Yes |
Do you need to choose only one development option?
No, you can combine copy activities, data flows and SSIS in the same pipeline depending on your business scenario.

What is my personal pick up?
Without a doubt, Azure Data Factory pipelines using metadata-driven approaches is my pickup. It allows you to build large enterprise solutions quicky without sacrificing maintainability. It allows customers to easily extend the solution with new data assets.
What is your personal pick up? Leave a comment below.
Azure Data Factory Pipelines
Additionally, the main Azure Data Factory (ADF) objects are pipelines. Pipelines help you to group activities to design enterprise data movements. This includes copying data as well as applying transformations.
With pipelines, you can:
- Copy data from on-premises to Azure services
- Copy data between cloud services
However, not all the activities have the same cost. The stored procedure, lookup and copy data activities are more most cost-effect than using execute data flows or SQL Server Integration Services activities.
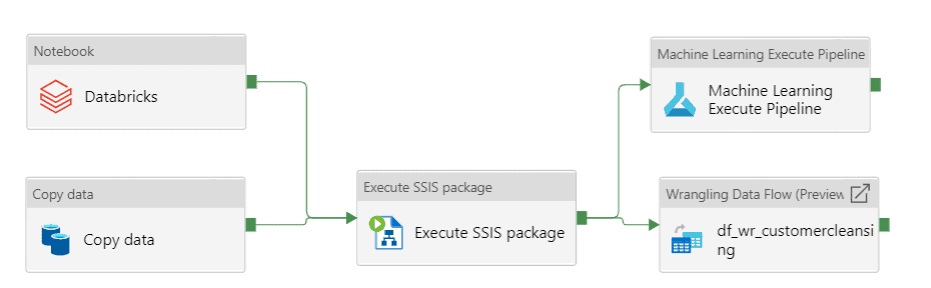
Some pipelines activities
The following picture displays how activities are grouped in Azure Data Factory.

You can have many activities within a single pipeline.

Other activities include:
- Copying Data
- Executing other pipelines
- Running ADF data flows
- Executing SQL Server Integration Services Packages
Pipeline parameters and variables
In addition, you can also define parameters and variables to make your pipelines more dynamic and reusable.

Azure Data Factory Mapping Data Flows
Azure Data Factory data flows offer 2 main options:
- Data flows
- Power Query
Data flows follow the ETL (Extract-Transform-Load) design pattern for data movements.

Data Flows
Azure Data Factory data flows offer a codeless experience for building and orchestrating enterprise data movements. They include transformation aggregation like lookups, slowly changing dimensions type 2, aggregations, or incremental loads.
Data flows are executed using Apache Spark.
Some of the key characteristics in ADF Data Flows include:
- Schema drift
- Debug flows without moving the data

Transformations

Schema drift

Debug / Preview

Power Query
Next up, wrangling data flows help you take advantage of the Power Query (M) engine. This engine is the same one that’s in Power BI or Excel.
This allows you to shift code from your Power BI solutions to Azure Data Factory if you run into any performance (volume or velocity) issues.
With Power Query, you can easily perform codeless data cleansing activities. Also, you can add custom columns, which is easier than common data flows.

Likewise, you can copy the Power Query code.

Execute Data Flows
It’s necessary to include data flows as part of the pipelines to be executed.

Select the data flow and the size of the cluster (Apache Spark) in the configuration settings.

Azure Data Factory SQL Server Integration Services Runtime (SSIS-IR)
SQL Server Integration Services (SSIS) has been around since 2005. Now, you can take advantage of a managed platform (Platform-as-a-Service) within Azure Data Factory (PaaS).
If you have made a large investment in SSIS and the solution still for purpose, you can lift and shift the solution to Azure Data Factory. There, you can execute it in a managed environment. Use copy activities or data flows to load any new data assets.
A managed environment means that you don’t need worry about hardware, OS, middleware or patching.
Follow the next steps to create an SSIS IR.

After that, configure the IR.

Finally, define where your SSIS catalog is.

The latest version of SSIS Visual Studio allows you to deploy to SSIS IR directly.

Execute SSIS Packages in Azure Data Factory
Once you’ve created your SSIS IR, you can execute packages in pipelines. Additionally, it’s possible to continue using environments and master-child packages.

What’s Next?
In upcoming blog posts, we’ll continue to explore Azure Data Services features.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!

4 Responses
Lou
12 . 11 . 2020Great Article!
David Alzamendi
24 . 11 . 2020Thank you for your feedback Lou 🙂
Koos van Strien
19 . 11 . 2020Great write-up! There’s one thing I’d like to add though:
The performance of the Copy Activity is not only based on the performance of your source / target. The copy activity itself uses Data Integration Units as well, which also determine performance. You will be charged for that usage (around # of used DIUs * copy duration * $ 0.25 / DIU hour)
Usually, these scale automatically, but you can set the number manually if you like to (go to the *settings* tab of your copy activity)
David Alzamendi
24 . 11 . 2020Hi Koos van Strien,
Thank you for your comment!
I have included that as part of the engine section for the copy activity to make sure that everybody is aware of the Data Integration Units (DIUs) concept. DIUs deserve its own blog post to be able to expand a little bit more on them, I have included this idea in my backlog.