


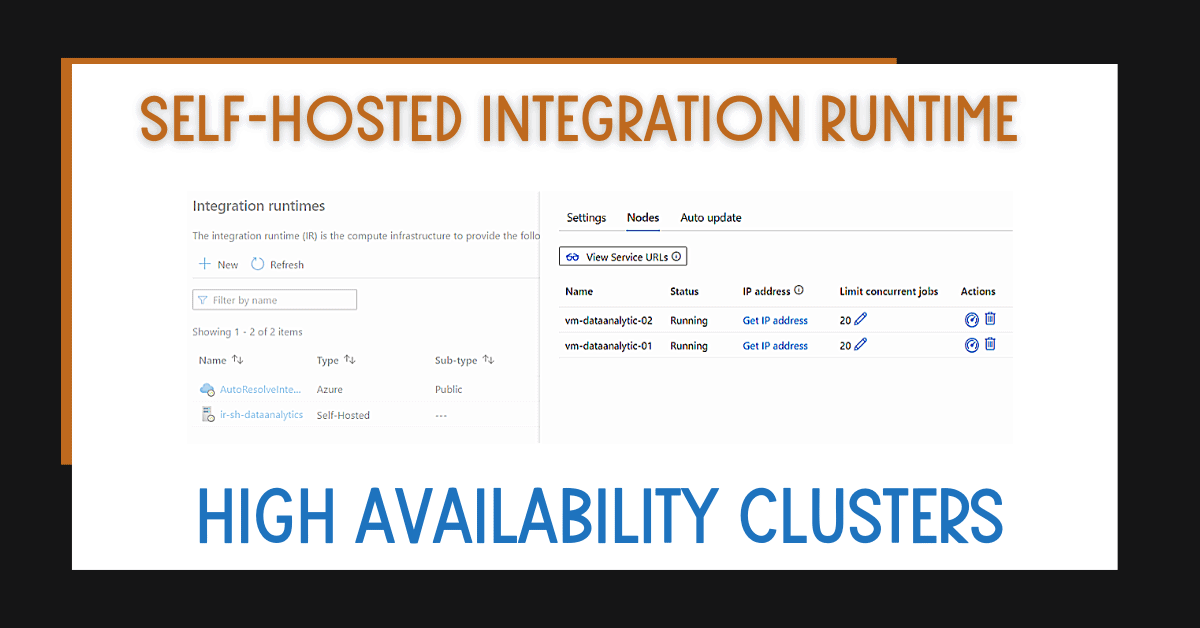
In this blog post, I’ll show you how to configure an Azure Data Factory or Synapse Analytics Self-Hosted Integration Runtime High Availability Cluster for your mission-critical workloads.
Table of Contents
Why should I set up a self-hosted integration runtime cluster?
To begin, if you are working with Azure Data Factory or Synapse Analytics and using a self-hosted integration runtime, having a cluster provides the following benefits:
- High availability for mission-critical workloads (production as an example) – availability to apply operating systems updates and patches without outages. This includes:
- In case one of the nodes goes offline
- Availability to apply operating system updates and patches without outages
- Increase performance by scaling out with multiple nodes.
- Overcome limit of concurrent jobs (20) in a single node
- A copy activity can take advantage of multiple nodes
- You can have up to 4 nodes in a self-hosted integration runtime cluster. This really increases the resiliency of your workloads.

Creating a Self-Hosted Integration Runtime Cluster
The initial creation of a self-hosted integration runtime cluster for Azure Data Factory or Azure Synapse Analytics isn’t much different from setting up only one node.
First, go to the Manage Hub. Then go to integration runtimes and click “new.”

Next, select the self-hosted integration runtime option.

Then, define a name for your self-hosted integration runtime.

Finally, to set it up:
Option 1) Select the express setup if you are inside the server where you want to install the self-hosted integration runtime
Option 2) Download the executable file and copy it to the server where you want to install the service

Installing a Self-Hosted Integration Runtime in First Node
If you are using express setup, it will download, install, and configure the service for you.
If you are using manual setup, navigate to the server where you want to install the self-hosted integration runtime. Execute the installation file.

Complete the installation by following the wizard.

Copy one of the keys into the configuration box and register it.

Make sure that if you are planning to add multiple nodes, you assign meaningful names to each node. Enable and configure remote access, it is required for having multiple nodes.

Configure remote access.

If the configuration of the self-hosted integration runtime node finishes correctly, the following window will be displayed.

If you launch the configuration manager, you’ll see the status of the service.

Don’t forget to generate a backup in case you need to restore your self-hosted integration runtime.
Back in Azure Synapse Analytics or Azure Data Factory, you’lll see the node added as your integration runtime.

Enable Remote Access in Existing Self-hosted Integration Runtime
If you’ve created a self-hosted integration runtime in Azure Data Factory or Synapse Analytics without remote access enabled, you can enable it in the configuration manager of the service.
Go to settings and enable the option as described below.

To enable remote access, you need to restart the service.

Once remote access is enabled, you can set up more nodes.

Installing a Self-Hosted Integration Runtime in Second Node
Now, let’s add one more node to an existing Azure Data Factory or Synapse Analytics self-hosted integration runtime.
First, install the self-hosted integration runtime service (same as initial node).

When configuring the node, copy the key inside the configuration manager.

Make sure you give a meaningful name to the new node for your Azure Data Factory or Synapse Analytics self-hosted integration runtime.

Configuring remote access is required when adding multiple nodes.

Once you’ve finished configuring the service, launch the configuration manager.

The new node will be connected to the existing integration runtime.

In Azure Data Factory or Synapse Analytics, the new node will become available.

Summary
To sum up, having self-hosted integration runtime clusters in production and mission-critical workloads is highly recommended. Luckily, they aren’t difficult to configure.
This also enables you to optimize workloads by scaling out and running more activities at the same time.
Don’t forget to enable remote access and backup the configuration of your self-hosted integration runtime in case you need to restore it later.
What’s Next?
In upcoming blog posts, we’ll continue to explore some of the features within Azure Services.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
As always, please leave any comments or questions below.

4 Responses
George
30 . 09 . 2021Hi,
Do you have any experience connecting Data Factory to a SQL cluster running on Azure virtual machines? The VMs don’t have public IPs. Do you know if connectivity through Integrated Runtime is supported on SQL cluster or do-able through Private Links?
Scott
25 . 10 . 2022Great blog post! You da man.
David Alzamendi
07 . 11 . 2022Thank you for your feedback Scott!
Raghu
28 . 04 . 2023How does the system know which node is running, if there is an update of Java on one of the VMs and SHIR doesnot support parquet files because of this update, pipeline fails.
Can we disable one of the nodes in some way when there are any issues with any of the nodes? Can we change the status of nodes somehow?