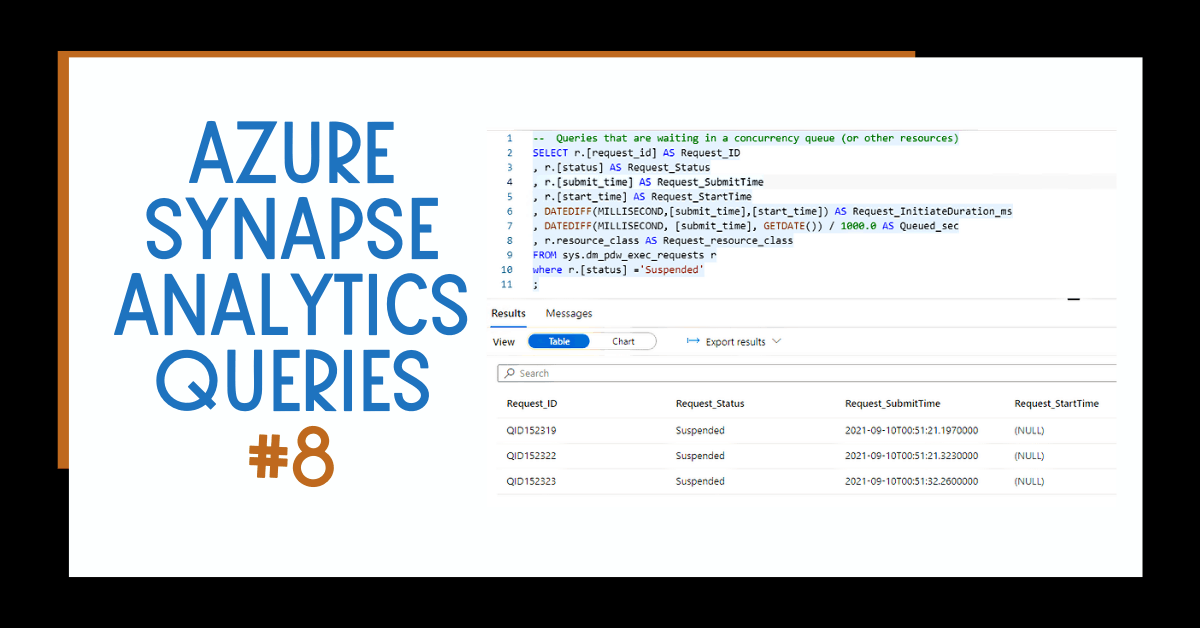
The results display a summary of table sizes and distribution types.

Azure Synapse Analytics Table Size by Distribution Type Query
Table size by distribution type query:
Results:

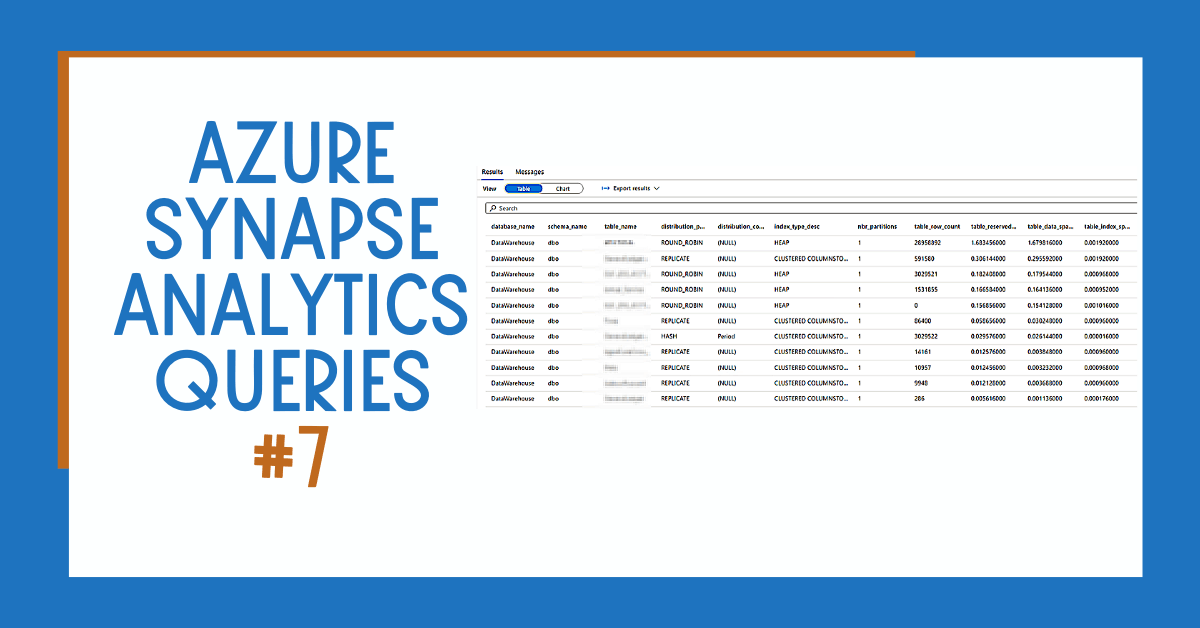
Azure Synapse Analytics Table Size by Index Type
Table size by index type query:
Results:

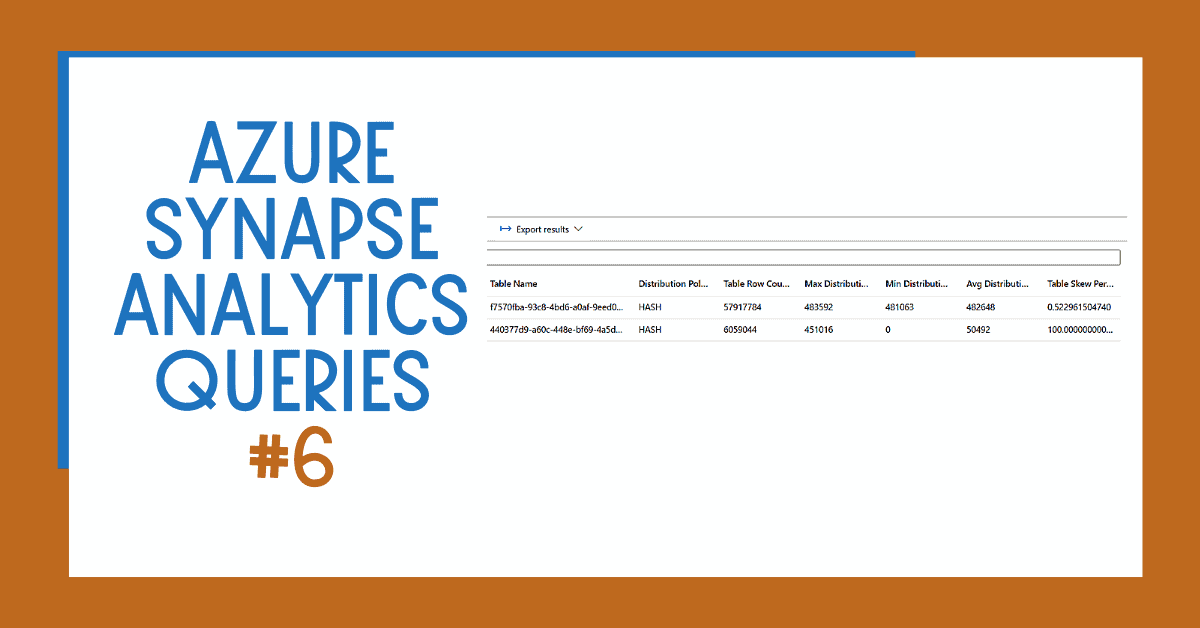
Azure Synapse Analytics Distribution Size Summary
Distribution size summary query:
Results:

Summary
In summary, correct table design is critical to maintain and improve the performance of your queries in Azure Synapse Analytics SQL Dedicated Pools. The queries mentioned in this post will help you identify how data is distributed across different tables. Then, you can choose an optimal table type for your data assets.
WHAT’S NEXT?
In upcoming blog posts, we’ll continue to explore some of the features within Azure Services.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
As always, please leave any comments or questions below.