


Data skew is one of the most important considerations when working with Azure Synapse Analytics. Data skew is the uneven distribution of data across data storage distributions in SQL Dedicated Pools. In this post, you’ll learn how to monitor the data skew in your Azure Synapse Analytics SQL Pool.
Table of Contents
About Data Skew
To begin, data skew is when your data is not distributed correctly across different storage distributions. This decreases the performance of your Azure Synapse Analytics SQL Dedicated SQL Pools. This term also applies to other big data systems, including working with Apache Spark pools or other areas like machine learning or reporting.
Firstly, the main idea when understanding data skew is that a high data skew percentage is not recommended. This causes some compute nodes to work harder (more processing query time) to read and retrieve information from the tables.
Azure Synapse Analytics Dedicated SQL Pools have 60 storage distributions and when choosing the distribution key for your hash distributed tables (aka DISTRIBUTION = HASH in the creation of the table), your goal is to select the optimal column for distributing the information evenly.
Another key point is making sure your key is the same across different tables that will be queried or joined together to avoid shuffle data movement operations.
This concept mainly applies to Hash Distributed tables.

This is because replicated tables (aka DISTRIBUTION = REPLICATE) copy information (all the rows in the table) across all the available compute nodes. Then, round_robin (aka DISTRIBUTION = ROUND_ROBIN) distributes information randomly across the storage distributions.
Analysis Azure Synapse Analytics Data Skew
The following query will help you understand if there is data skew in your Azure Synapse Analytics Dedicated SQL Pools tables.
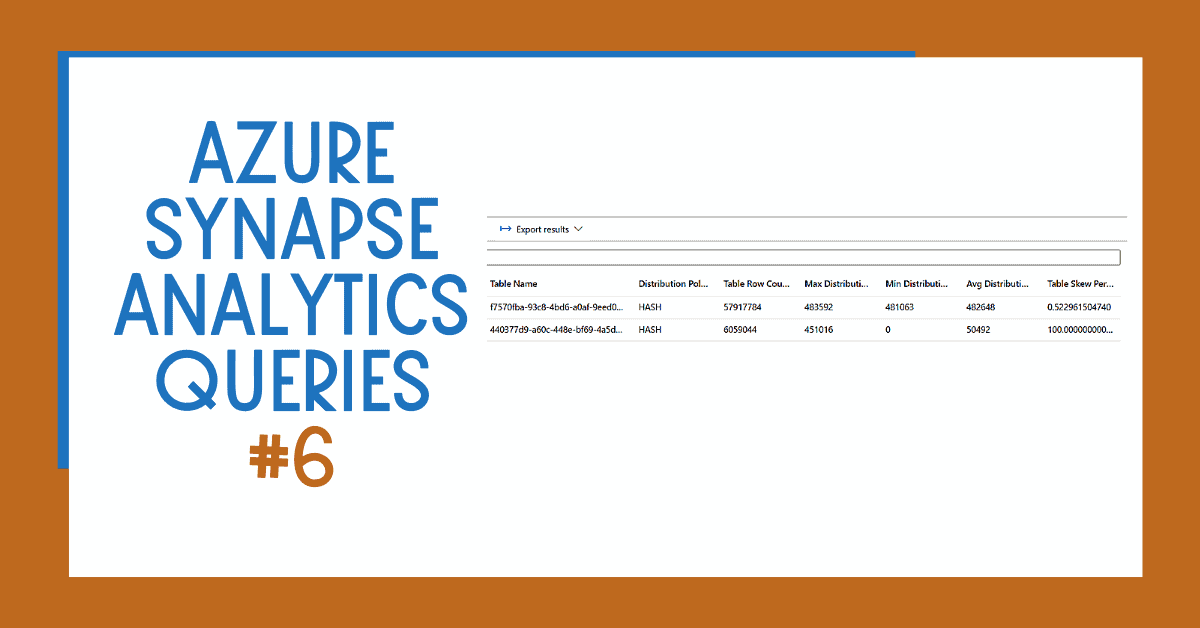
Query results with data skew percentage for each one of your Azure Synapse Analytics tables.
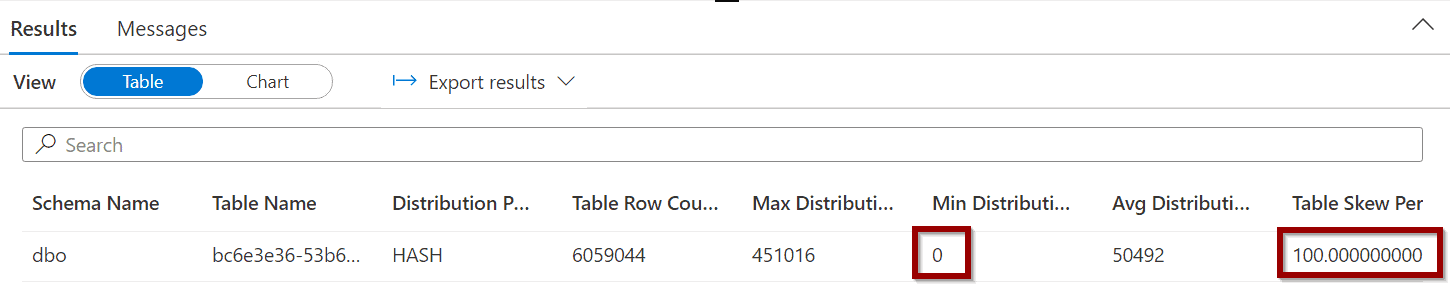
You can see in the results that one of my tables has a 100% data skew. This is because some of the storage distributions don’t have any data. This is due to an incorrect design decision when choosing the distribution key for the table.
So, what does distribution look like? In the image below, you can see that the data skew has reduced to 0.52% after changing the distribution key.

Summary
To summarize, you have seen a critical query that will help you identify data skew (which is not recommended) in your Azure Synapse Analytics Dedicated SQL Pools. This query will help you select optimal distribution keys for each one of the tables when the information is hash distributed.

1 Response
Denis
28 . 01 . 2023Hi,
Problem :
There’s an issue. Your query result contains duplicates rows. Real row count x 2!
Reason :
sys.dm_pdw_nodes cointain 2 rows : CONTROL, COMPUTE.
> JOIN sys.dm_pdw_nodes pn ON nt.[pdw_node_id] = pn.[pdw_node_id]
Solution:
in WHERE clause, add:
and pn.[type]=’COMPUTE’