Nowadays building an Azure SQL Database and Synapse SQL Pool Azure DevOps Continuous Integration (CI) and Continuous Deployment (CD) pipeline using Azure DevOps is easier than ever.
I frequently come across scenarios where the deployment of Azure SQL Databases and Synapse SQL Pools between environments (Development/Test/Acceptance/Production) is manual.
To make sure my customers enjoy the journey, I always suggest starting with the solution below and then expanding – depending on more advanced and detailed requirements.
If you are working in the data space, this is a must. With many organizations, adopting agile methodologies and a strong process to release changes is required.
Table of Contents
Grant Azure DevOps Access to Azure Synapse Analytics or Azure SQL Database
Before you start creating your Azure SQL Database and Synapse SQL Pool Azure DevOps CI/CD solution, you need to create a service connection. You also need to grant access to Azure DevOps and your pipelines to deploy changes in the database.
Create a service connection.

Create an Azure Resource Manager connection.

Select Azure Service Principal.

Select the subscription or management group scope and click Save.

Now, select the connection and select Manage Service Principal.


Copy the display name so you can give it access to the database.

In your database, copy the following command and replace information with the name of your app.
create user [YourAppId]
from external provider
exec sp_addrolemember 'db_owner', 'YourAppId' 
You can get the name of your Azure DevOps app by clicking the service connection. If you don’t have one, create one that you can use.
Note: If you are going to create users and logins as part of this pipeline, you will require more access so the pipeline can read the Azure AD directory.
##[error]Error SQL72014: .Net SqlClient Data Provider: Msg 37353, Level 16, State 1, Line 1 Server identity does not have Azure Active Directory Readers permission. Please follow the steps here : https://docs.microsoft.com/en-us/azure/azure-sql/database/authentication-aad-service-principal

Create New Azure DevOps Branch in Your Code Repository
First, make sure you create a different branch. Use it to automatically deploy changes to the next environments.
Create a new branch, for example, a Publish branch. This will help ensure that only changes that are merged with the new branch and are ready to be released are deployed to the next environment.
Click here to learn how to Integrate Azure SQL Databases or Synapse SQL Pools with Azure DevOps

Go to your repository and click New branch.

The new branch will be based on the collaboration branch. (In this case, master.)

Create Azure SQL Database and Synapse SQL Pool Azure DevOps CI/CD
The next step is to create an Azure SQL Database and Synapse SQL Pool Azure DevOps CI/CD solution (it will use YAML). First, go to the section of the pipeline and create a new one.

Select the repository where your database project is. This will be the repository as well for the pipeline.

Select the Azure Repos Git option.

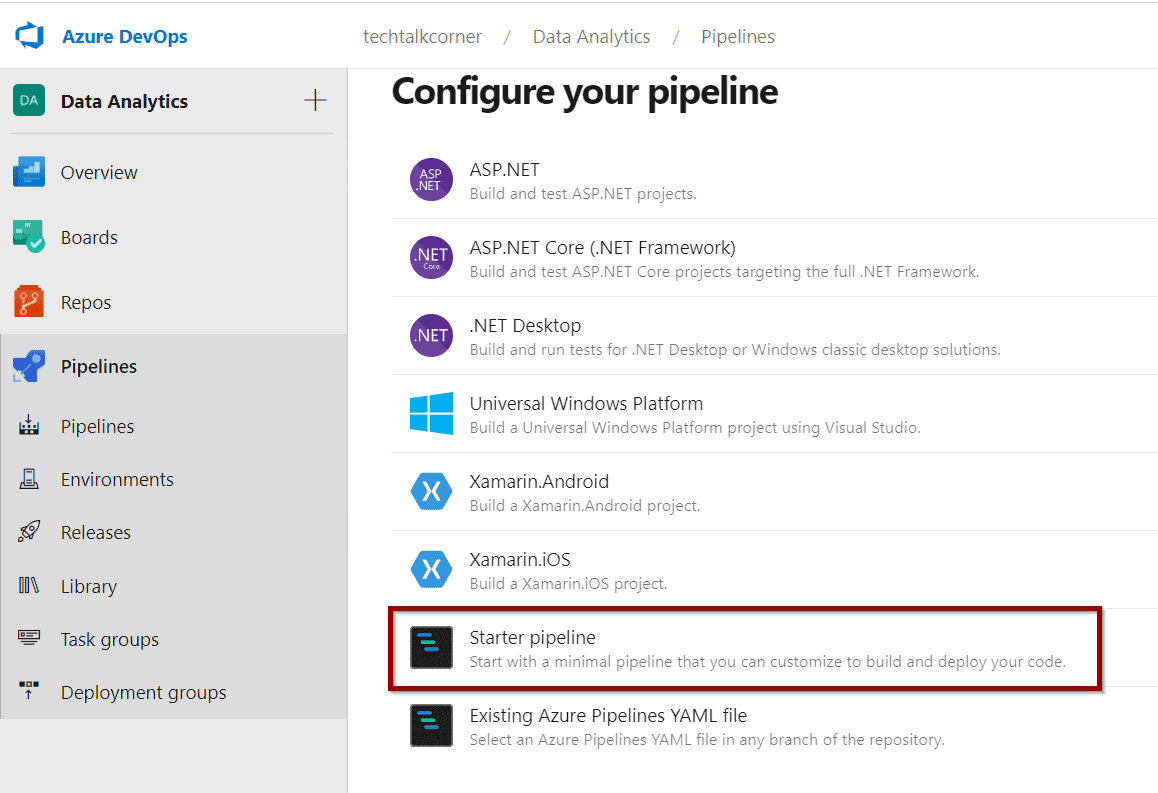
Finally, paste the following pipeline definition:
# Pipeline to deploy database changes to next environment
# Author: David Alzamendi
# https://techtalkcorner.com/
# Specify to use VM image of Microsoft-hosted pool
pool:
vmImage: 'windows-latest'
trigger:
- Publish # You can change this to None if you want to trigger it manually
# Build database solution
steps:
- task: MSBuild@1
displayName: 'Build Visual Studio solution'
inputs:
solution: '**/*.sln'
msbuildArchitecture: 'x64'
# DACPAC file for deployment (DACPAC is useful for capturing and deploying only schema)
- task: PublishBuildArtifacts@1
displayName: 'Publish DACPAC file'
inputs:
PathtoPublish: '$(Build.SourcesDirectory)\Adventure Works Data Warehouse\bin\Debug' # Modify folder path
ArtifactName: 'DACPACs'
publishLocation: 'Container'
# Configure destination server and deploy, access to the database is required
- task: SqlAzureDacpacDeployment@1
displayName: 'Deploy DACPAC changes'
inputs:
azureSubscription: 'AzureDevOps' # Service connection name
AuthenticationType: 'servicePrincipal'
ServerName: 'syn-dw-aue-prd.sql.azuresynapse.net' # Server name
DatabaseName: 'DataWarehouse' # Database name
deployType: 'DacpacTask'
DeploymentAction: 'Publish'
DacpacFile: '$(Build.SourcesDirectory)\Adventure Works Data Warehouse\bin\Debug\Adventure Works Data Warehouse.dacpac' # Modify folder path
# AdditionalArguments: '/p:BlockOnPossibleDataLoss=False' # User this argument if you want to unlock data loss by removing columns or altering schemas of existing tables
IpDetectionMethod: 'AutoDetect'Your solution is ready to be tested. Make sure you change the required values, the name of the pipeline and the “Save and Run” option.

The pipeline definition looks at any new commits in the Publish branch. Once you check in new changes in this branch, it will trigger automatically.

Test Azure DevOps Azure SQL Database and Synapse SQL Pool CI/CD
Now you can execute the pipeline to test it.
The following database is empty:

Merge your changes with your Publish branch and the pipeline will trigger automatically.

And the tables are available in the production database.

FAQ
Can I add new columns or modify the schema when the table has data?
Only the new changes will be applied. Data will not be lost.
Can I remove columns or modify the schema when the table has data?
You will get the following error:
##[error]Error SQL72014: .Net SqlClient Data Provider: Msg 50000, Level 16, State 127, Line 1 Rows were detected. The schema update is terminating because data loss might occur.
##[error]Error SQL72045: Script execution error. The executed script:
##[error]IF EXISTS (SELECT TOP 1 1
##[error] FROM [dbo].[DimAccount])
##[error] RAISERROR (N’Rows were detected. The schema update is terminating because data loss might occur.’, 16, 127)
##[error] WITH NOWAIT;
##[error]System.Management.Automation.RemoteException
To overcome this challenge, add the following parameter.
AdditionalArguments: '/p:BlockOnPossibleDataLoss=False' 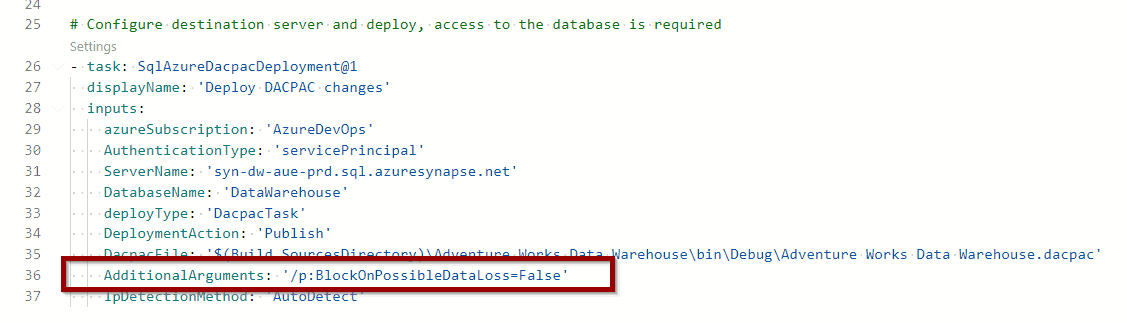
Summary
In summary, you now have a functional solution for deploying Azure SQL Database and Synapse SQL Pool database changes between environment using Azure DevOps and a CI/CD approach.
You can now extend this solution with more advanced capabilities:
- Add pipeline variables and use Azure Key Vault to store connection strings
- Add gates, checks and approvals
WHAT’S NEXT?
In upcoming blog posts, you’ll learn how to easily enable Continuous Integration and Continuous for this solution.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
As always, please leave any comments or questions below.