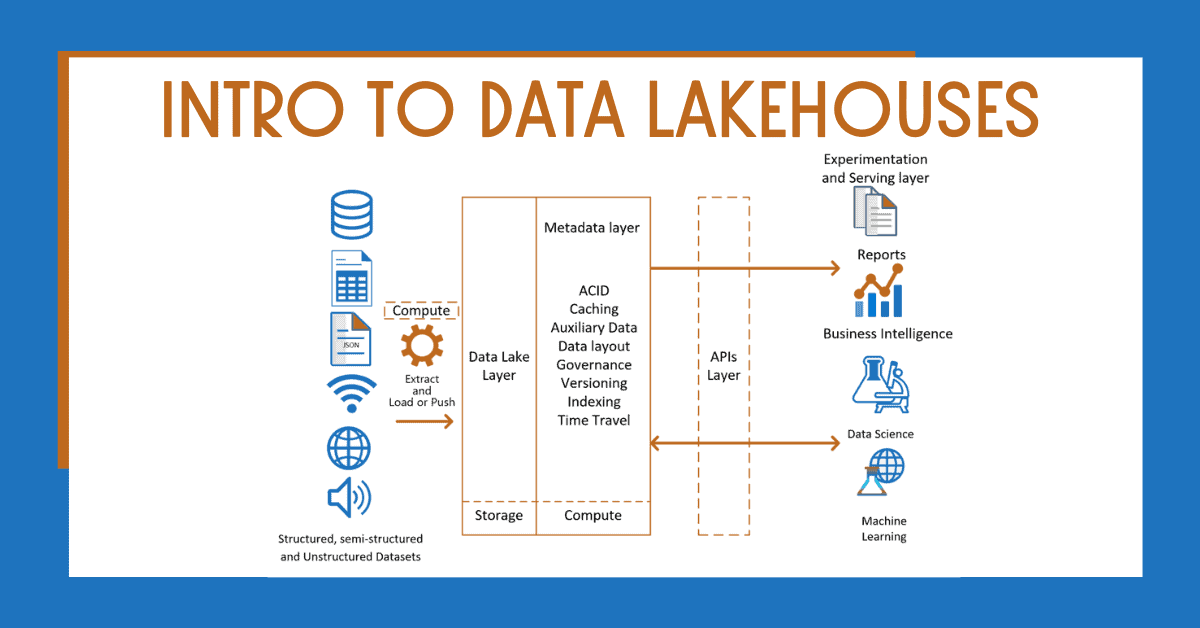
Data Lakehouses are a new open architecture paradigm that combine data warehousing and Data Lakes to create a single platform. This platform optimizes resources and mitigates some of the existing challenges in Data Lake and data warehouse architectures. This blog post will define what a data lakehouse is and why you should consider it for your designs.
Table of Contents
What is a data lakehouse?
To begin, data lakehouses combine the best of data warehousing, Data Lakes and advanced data analytics to create a single platform. Users can build analytical solutions while minimising costs and overcoming existing challenges.
Data lakehouse architecture is defined in multiple layers:
- Storage layer
- Metadata layer
- APIs layer
- Experimentation, Presentation / Serving layer

Data Lakehouse Data Lake / Storage Layer
The Storage or Data Lake layer in Data Lakehouses is used to store structured, semi-structured and unstructured datasets using open-source file formats (example: ORC or Parquet files).
With the rise of cloud technologies like Azure Data Lakes and AWS S3, storage has not only become fast but also cheap, accessible and limitless.
This layer is decoupled from computing, allowing the compute power to scale independently from storage.
Data Lakehouse Metadata Layer
The Data Lakehouse Metadata layer allows you to govern and optimise your data assets.
This layer allows you to have data warehouse capabilities that are available in relational database management systems (RDBMS. Examples are creating tables, slowly changing dimensions, using upserts, defining access and features that help match and improve the performance of RDBMS.
The metadata layer includes features like:
- Indexing
- Schema enforcement
- Caching
- Access control
- Indexing and statistics
- Versioning and time travel
- Partitioning and bucketing – allow you to distribute data using different predicates (like filters) to optimize reads
- ACID transactions to guarantee data consistency
- Atomicity: guarantees that each transaction is treated as a single “unit”, which either succeeds or fails completely. All or nothing transaction.
- Consistency: ensures that when a transaction starts and when it finishes, it will be in a consistent state.
- Isolation: multiple transactions can be executed at the same time without affecting each other.
- Durability: guarantees that once a transaction has been committed, it will remain committed even if the system fails.
This layer does not replace critical thinking for data warehouse workloads. You still need to look at following data warehousing best practices, applying complex transformations and performing data cleansing.
Data Lakehouse Metadata APIs Layer
In the Data Lakehouse metadata APIs layer, a set of APIs is used to access information.
The APIs layer creates a level of abstraction that allows developers and consumers to take advantage of different libraries and languages. These libraries and APIs are highly optimized for consuming your data assets in your Data Lake layer.
The best example is to think about DataFrames APIs or SQL APIs in Apache Spark.
Depending on the APIs and type of workload, you might want to assign different types of computing power (CPUs/GPUs).
Data Lakehouse Experimentation, Presentation / Serving Layer
The Data Lakehouse experimentation, presentation / serving layer brings great benefits to developers and data consumers by allowing them to create actionable insights while importing the information from a single platform.
Data Lakehouses enable data warehouse professionals, report writers, data analysts and data scientists to create solutions that enrich the platform and avoiding data duplication during the process.
Data lakehouses enable an ecosystem where data professionals can all contribute. Whether you are creating Power BI reports or Machine Learning solutions, the data comes from the same platform and offers different types of resources depending on your workload.
Why implement a data lakehouse?
Data lakehouses have been defined to solve some of the existing challenges in legacy data warehouse implementations, as well as the combination of Data Lake and data warehouse implementations.
The main focus is to optimize resources while enabling the platform to enable advanced data analytics like machine learning and data warehousing workloads.
Let’s look at why you should consider data lakehouses by examining challenges for:
- One-tier architecture (Traditional data warehouses)
- Two-tier architecture (Data Lake and data warehouse)
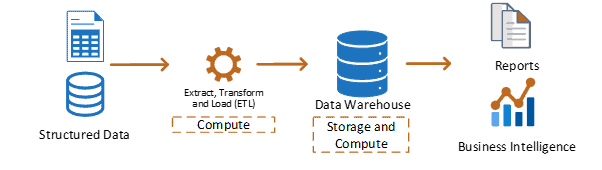
Traditional Data Warehouse Challenges
First, the following challenges have been discovered in data warehouse environments where data assets flow directly from source systems to a data warehouse database.
- Lack of advanced data analytics support
- Lack of support for non-structured datasets
- Legacy data warehouses don’t decouple storage from computing, making it costly to scale
- Traditional ETL approach that has limitations on large volumes of data
- Uses traditional relational database management systems (RDBMS)
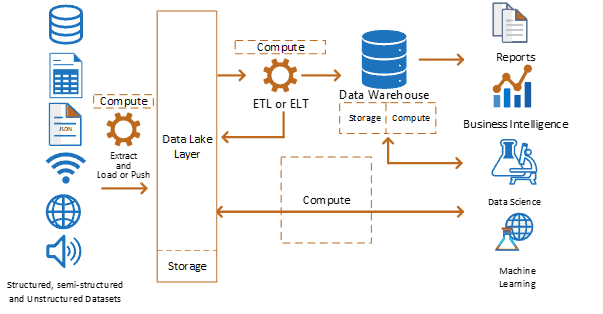
Data Lake and Data Warehouse Challenges
Secondly, this architecture is well known and has been adopted by thousands of organizations.
While technology providers keep releasing new features and improving these architectures, there are some existing challenges:
- Duplication of data and resources: including human effort and resources (storage and compute). This increases the operational cost and development effort
- Increase of complexity: two tiers need to be maintained and where to develop solutions
- Risk of failure increases due to the increase of data movement processes
- Limited support for advanced data analytics (this requires more development using different tools)
- Not many organisations are taking advantage of Data Lakes, or they are poorly defined
How to Build a Data Lakehouse
If you are looking to build a data lakehouse, the characteristics mentioned above related to the metadata layer for Data Lakehouses are already available in Delta Lake. Also, the metadata APIs layer is available in Apache Spark and highly optimised in Databricks.
Delta Lake is an open-source storage layer that includes a metadata layer and is available in Apache Spark.
Apache Spark Open-Source Foundation and Databricks are taking data analytical solutions and data architecture to the next level by making these capabilities accessible to everyone. They are helping define the data state in years to come.
This doesn’t mean that you can’t build a data lakehouse using on-premises technology. However, it will be more rigid and less cost-effective since you need to acquire the resources up-front. In contrast, in the cloud you can assign them as required.
It’s necessary to consider that this architecture has been implemented across some organisations, but it is in an early stage and will mature more in the future.
Streaming / Near-real Time Data
Data Lakehouses help you processing real-time / streaming data as required by decoupling storage from compute. They also take advantage of big data and edge technology.
Near-real time workloads can be achieved by assigning the required resources (compute power) to work with these requirements.
The overall time to process and make data available in the serving layer will decrease as it doesn’t need to go through different layers (like in Data Lake and data warehouse architecture).
Summary
Today, we took a brief look at Data Lakehouses and how they are trying to solve some of the existing challenges in the data analytics space.
Reference material:
- Delta Lake (https://delta.io/)
- Databricks (https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html)
- CIDR paper for Data Lakehouses (http://cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf)
What’s Next?
In upcoming blog posts, we’ll continue to explore some of the features within Azure Data Services.
Follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
You can also connect with me on LinkedIn.
Please leave any comments or questions below.