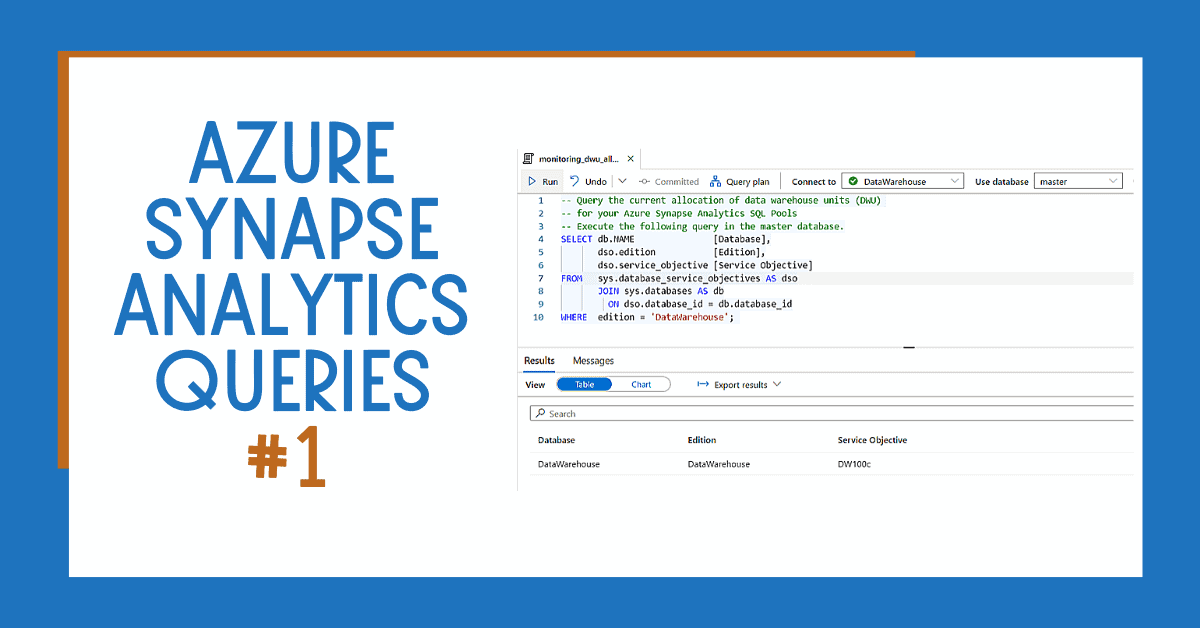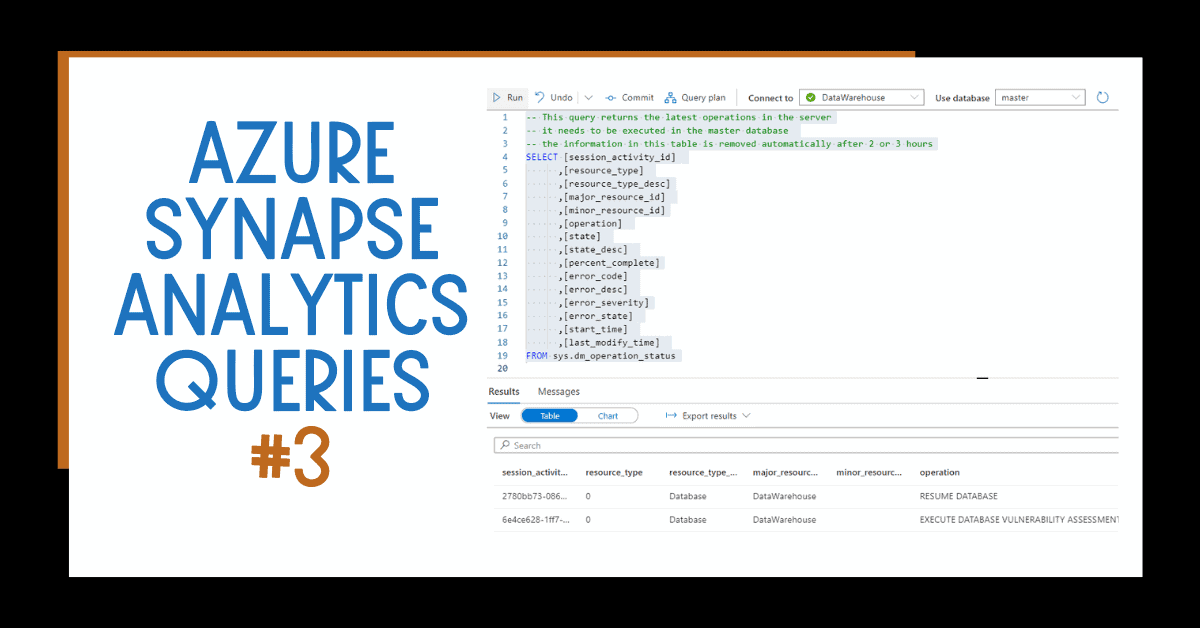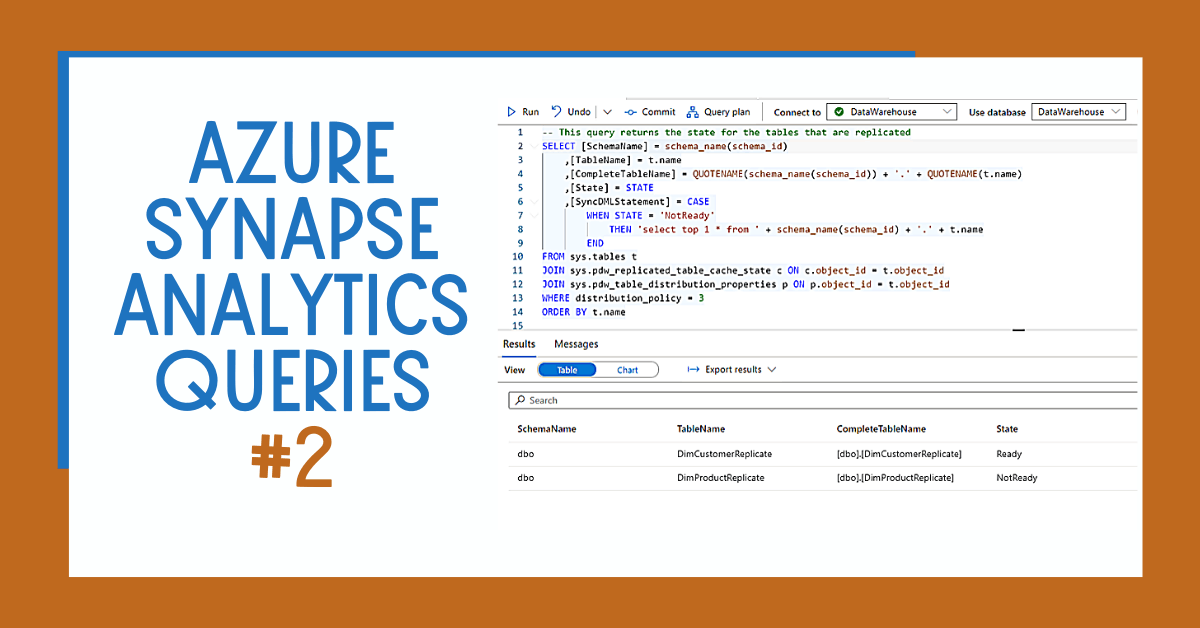

WHAT’S NEXT?
In upcoming blog posts, we’ll continue to explore some of the features within Azure Services.
Please follow Tech Talk Corner on Twitter for blog updates, virtual presentations, and more!
As always, please leave any comments or questions below.